(已修改)原来是当初做了一段时间PostgreSQL DBA后,做了个整体的整理,全文篇幅很大,显得很啰嗦,更像是一个学习笔记;后续再一些具体模块有了更细致的总结后,对本文进行了一些删减;目前只作为引子,希望能够帮到第一次了解PostgreSQL的同学,有个大概的认识,更具体的细节在其他的文章中。
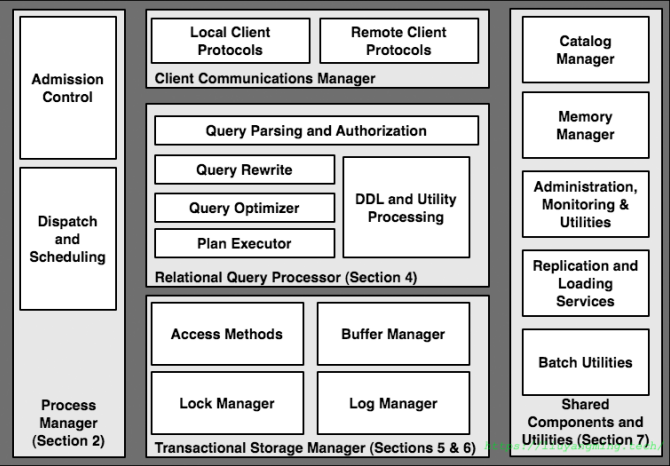
一个数据库的主要模块基本如上图所示,PostgreSQL也不例外;本文基于以上模块对PostgreSQL进行梳理。
存储
存储方面主要涉及内存与磁盘的布局;了解PostgreSQL是如何组织自己的数据的。
临时内存分配
一般我们说的db内存管理,常常是指的buffer pool,在PostgreSQL中,就是shared_buffer;实际上,数据库系统中系统中,还有一些需要内存的任务;比如,Selinger方式的查询优化器中的动态规划需要额外的空间,以及sort和hash等操作;内存管理一般是context-based方式的内存分配;这种方式可以方便地进行底层的垃圾回收,特别是在分阶段的查询执行中,上一阶段结束即可删除该上下文的内存空间,同时申请下一阶段的内存。另外,这种方式避免了多量小块内存的多次malloc/free调用,提高效率;
在PostgreSQL中,内存管理一般指:
work_mem:太大,连接多了,占内存;太小,sort、hash计算慢;不用担心work_mem不够,可以降级用磁盘(temp_file_limit);
temp_buffers:临时表
maintenance_work_mem:维护进程的mem,可以比work_mem大一点
autovacuum_work_mem:特别维护进程:vacuum的mem,默认是maintenance_work_mem的大小
缓冲区管理
All problems in computer science can be solved by another level of indirection
—— David Wheeler, fundamental theorem of software engineering
缓冲区是为了提高IO效率的一个中间层,db分配一个固定大小或可动态分配的内存空间作为buffer pool;以disk page的大小作为一个单元,且和disk page的结构相同;这避免了读写时的Marshall/Unmarshall的cpu代价,以及避免了压缩展开带来的管理复杂度。
其实OS本身同样有一个buffer,但是OS的buffer关注的是性能,一般采用的是read-ahead/write-behind的方式;而DB除了控制数据的写在哪,更关键地是,还要控制写入的顺序。如果使用OS buffer,OS buffer可能会打乱DBMS的写入逻辑,这会有问题,违反ACID的正确性保证:
PostgreSQL的BufferPool中有这三类对象:
shared_buffers:shared_buffers设置通常是在OS内存的25%~40%之间;设置小了,当然会影响到db的性能;如果设置大了,会影响到checkpoint的速度,并且可能需要调大max_wal_size。PostgreSQL的刷脏页有两个后台进程参与bgwriter / checkpoint ,这里描述了checkpoint的相关逻辑。wal_buffers:一般是shared_buffers的1/32的大小,但是有个范围[64kB,wal_segment_size]。每次事务commit都会将wal_buffers写入磁盘,因此提高wal_buffer并没有太大的作用,只是当同时提交很多事务时,会提高写入性能。这里对PostgreSQL的WAL有较详细的描述。Commit LOG:pg_clog文件的缓存
PostgreSQL的缓冲器更多是利用BufferPool与Page Cache进行的双层Buffer,虽然Page Cache不是PostgreSQL的模块,但是PostgreSQL的性能有时依赖于Page Cache的状态,这篇详细讨论了PostgreSQL与MySQL在BufferPool 上的不同,以及原因。
访问方法
访问方法,即访问磁盘的方法,就是磁盘布局,通常意义上的一级索引与二级索引。在PostgreSQL中,分别指的是直接Heap表访问和通过索引访问。
这里需要提到一点,PostgreSQL当通过索引的方法访问时,如果过滤条件中,有索引键,那么返回的行数就不是全表,注意观察EXPLAIN命令,这时过滤条件叫Index Con,而不是Filter。
一个table对应的物理文件有三个:
[postgres@localhost 16385]$ ll 353947*
-rw------- 1 postgres postgres 11567104 Jun 15 09:51 353947
-rw------- 1 postgres postgres 24576 Jun 15 09:51 353947_fsm
-rw------- 1 postgres postgres 8192 Jun 15 09:51 353947_vm
353947_fsm(free space map):一个二叉树,叶子节点是某个页上的FreeSpace,一个字节代表一个页;上层节点是下层信息的汇总;用来在insert或者update的时候,找FreeSpace;
353947_vm(visibility map):一个bitmap,
1代表页中的所有tuple对所有tranaction可见353947 : Heap Table
在HeapTable中就是一个个的Page,这里对其有详细的描述。
由于PostgreSQL的MVCC特性,在说到PostgreSQL的磁盘管理时,必须得提到Vacuum这个操作,这是PostgreSQL DBA的必修课,在MVCC中,一并总结。
存储可用性
和存储相关的,还有一个概念就是可用性;主要是指通过冗余的方式,进行冷备或者热备,来确保服务的可用性。
冷备——PITR
有一个某一时刻a的全量备份,以及之后的归档文件;就可以恢复到a之后的指定时间点;
BaseBackup:pg_basebackup命令,主要就是注意做热备的时候;wal_keep_segment可以的话,调大点
archiver process:两个占位符:%p %f;三个配置项:mode/command/timeout;注意开了归档,确保command是有效的,要不磁盘空间会被wal占满;
热备——Replica
PostgreSQL可以级联流复制,所以在一个基于流复制的Cluster中,有以下三个角色
- primary master
在这个节点上,一定要设置好wal_level,这决定了整个集群的复制级别;10中有了logical,之前的archive和hot standby整合成replica了;如果采用同步提交打开,需要master上设置好synchronous_standby_names(有first和any两种模式);
由于主从的查询不一样,用到的tuple也不一样;为了防止master把slave用到的tuple给清理了,可以设置一下vacuum_defer_cleanup_age保留一定时间的老数据;也可以在slave中打开hot_standby_feedback,来向master知会slave上的查询状态;但是,这两种方式都可能导致表膨胀,所以通过old_snapshot_threshold强制设置一个老快照的上限;
- cascaded slave
承接上下游的关键节点,压力还是不要太大的好
- leaf slave
承接读流量
数据订阅(CDC)
数据库中存储的数据除了用户通过SQL查询外,还会在公司内部不同系统间进行订阅;类似的也有两种:
pg_dump/pg_dumpall:常用的导出数据的命令,如果数据有坏块,得处理一下;全局的对象用dumpall,比如role等;
逻辑复制:更细粒度的表级复制,PostgreSQL目前支持的是update insert delete操作的同步;这里有更加详细的描述。
计算
SQL解析
| Step | duty |
|---|---|
| parser | 通过 lex(词法)/yacc(语法) 检查SQL语法是否正确,得到parse tree; |
| analyzer | 基于catalog,检查table name/attr name/func等是否合法,得到query tree; |
| rewriter | 将CRUD类型的SQL语句进行重写;基于pg_rules这个用户自定义的规则,或者经验上的一些规则,比如视图展开,常量计算,选择下推,子查询展开; pg中的view就是基于规则实现的,在查询view的时候通过规则展开。 |
| optimizor | 按照cost,对于单个算子算子选算法,对Join顺序选最优的。 pg的cost分为两个阶段:startcost/runcost;分别有包含cpu与io相关的cost; 值得注意的是,相比于cost的计算方法,其实统计信息的更重要,这也很好理解,毕竟如果算法的输入是错的,结果可能就有偏差。 |
| executor | Pull模型 |
optimizor的统计信息通过stats collector收集;该进程有个UDP端口,系统中的别的活动,往这里发消息来收集;
和Pull执行模型相对的,还有Push的方式;在Push中,查询计划中有一些materialization points,也叫pipeline breaks;数据不是从前往后拉,是从后向前推,直到遇到某个pipeline breaks;如下图,原来的执行计划,分成了四段;
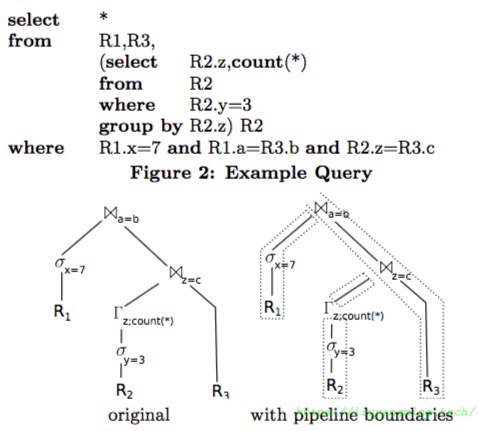
而PostgreSQL等常见的传统DB中,基本都是Pull模型;
This fact is often a surprise to people who have not operated or implemented a database system, and assume that main-memory operations are “free” compared to disk I/O. But in practice, throughput in a well-tuned transaction processing DBMS is typically not I/O-bound.
—— Hellerstein, Architecture of a Database System
这种模型产生时,也是一开始造出DB系统的年代,那时IO代价比CPU代价高;位于执行计划树顶端的操作,需要tuple的时候,向下面的操作符上请求tuple,以此类推, pull from top, 在这个模型中每个operator 都可以作为一个实现一个iterator接口,提供 open next close 的操作。
在这种模型中,每个tuple都需要一个next调用;其次,这个next的调用往往是一个虚拟函数或者函数指针的方式,这种方式的code locality不好,整体CPU代价比较高;并且不利于pipeline化。目前比较热门的clickhouse就是采用Push的模型,整体查询可以pipeline,大大提高了查询的执行效率。
并发控制
数据库的并发控制是为了确保多事务同时执行的结果等价于某种串行执行顺序的结果;这时需要确保每个事务的ACID特性:
- 原子:事务要么成功,要么失败;关注的是事务的状态只有两种:commit和aborted
一致:整个db的数据,从外部看总是一致的;事务处理的中间状态,对外是不可见的;这是要求的强一致性,需要严格加锁;
隔离:太强的一致性,带来性能的损失;适当的降低隔离性,提高性能;
- 持久:commit的数据必须确保持久保存了。
实现并发控制有三类方法:Two Phase Locking、Optimistic Concurrency Control和Multi-version Concurrency Control。PostgreSQL支持2PL和MVCC。MVCC简单说就是数据带上了版本号,这样不同的事务只能看到自己版本的数据,写不阻塞读。PostgreSQL的MVCC具体机理见——关于mvcc的另一篇。
监控
系统表
table:基本就是一些PostgreSQL中的一些概念的元信息,pg_trigger /pg_type/ pg_class/ pg_index/ pg_sequence 等等。
view:基于系统表或函数上的一个系统视图,pg_stat_*
系统日志
where
- log_destination:stderr, csvlog , syslog;csvlog需要
logging_collector = on - log_directory:
- log_filename
- log_destination:stderr, csvlog , syslog;csvlog需要
when
- log_min_duration_statement
what
- log_connections
- log_checkpoints
- log_duration
- log_lock_waits
- log_statement
- log_temp_files