SQL92与并发异常
ANSI SQL 为了预防三种不同的并发异常现象,定义了四个隔离级别。最严格的是Serializable,即,任何一个Serializable事务的并发执行都能保证产生和按某一顺序串行地执行它们相同的效果。由于Serializable的定义,在这个级别上这些现象都是不可能的(这并不奇怪:如果效果必须与一次运行一致,那么您怎么看到交互造成的现象?)。另外三个级别是根据异常现象来定义的,如下。
| 隔离级别 | 脏读 | 不可重复读 | 幻读 | 串行化异常 |
|---|---|---|---|---|
| Read Uncommited | Possible(NO PG) | Possible | Possible | Possible |
| Read Commited | Not Possible | Possible | Possible | Possible |
| Repeatable Read | Not Possible | Not Possible | Possible(NO PG) | Possible |
| Serializable | Not Possible | Not Possible | Not Possible | Not Possible |
NO PG
PgSQL中,部分隔离级别实现的比较严格。
RC避免 脏读
脏读例子:事务读到了另一个正在运行的事务未提交的数据;
| T1 | T2 |
|---|---|
| select a from t where b=3; | |
| update t set a = 5 where b =3; | |
| select a from t where b=3;(a = 5) | |
| Rollback; |
RR避免 不可重复读
事务重新读取之前读过的数据时,发现该数据被另一个提交的事务update了;脏读和不可重复很像,区别在于脏读在T2还未提交时,就读了。
不可重复读例子:
| T1 | T2 |
|---|---|
| select a from t where b=3; | |
| update t set a = 5 where b =3; | |
| commit; | |
| select a from t where b=3;(a = 5) |
在基于lock的并发控制中,t1在读取事务时没有获取读锁或者第一个select后,立马就释放了读锁;会导致t2读取到更新已经读过的但没提交的数据。解决方法就是在RR级别中,通过锁,使t1/t2进行串行化调度。
在基于mvcc的并发控制中,当t2发生提交冲突时,处理策略不够严格也会导致不可重复读。解决方法就是在RR级别中,通过只读取事务开始时版本的数据,保证在整个事务生命周期内数据是一致的,这也是PostgreSQL和MySQL都采用的实现方式。
提交冲突(commit conflict):
为了避免上述基于锁的并发控制中,t1/t2要串行化才能解决问题,mvcc通过多版本数据,允许t2先提交,这样读写不阻塞;
- 如果在SERIALIZABLE级别中,由于读的数据是事务开始时的快照,t1只有读不会出现问题;如果t1也对数据进行了变更,那么提交的时候,db会检查t1提交的结果和按照t1/t2(即,以事务开始时间算)顺序的串行结果是否一致,一致可提交,否则就是提交冲突;此时,t1需要回滚(这就发生了序列化错误)。
- 或者在RC中,由于读的数据是查询开始时的快照,同时也没有串行化保证,也不会有提交冲突。
S避免 幻读
由于另一个事务Insert了一条新数据,导致这个旧事务的某些查询结果变了,比如count(*)。
| T1 | T2 |
|---|---|
| select * from t where b >0 and b <5; (假设有2条数据) | |
| insert into t(a,b) values(1,3); | |
| commit; | |
| select * from t where b >0 and b <5; (多了一条) |
在基于锁的并发控制中,采用RR,意味着会将读出的数据行加锁。但是不会在表的某一范围(比如例子中只会对2条数据加锁)加锁,这样别的事务会在该范围内插入一条数据;后面同样的查询就会多出一条来。
其他异常
以上的SQL隔离级别标准并没有做到实现无关,基本就是基于Lock的并发控制中的隔离级别。在论文Generalized Isolation Level Definitions中,基于事务之间的读写依赖,提出了新的实现无关的隔离级别,如下。
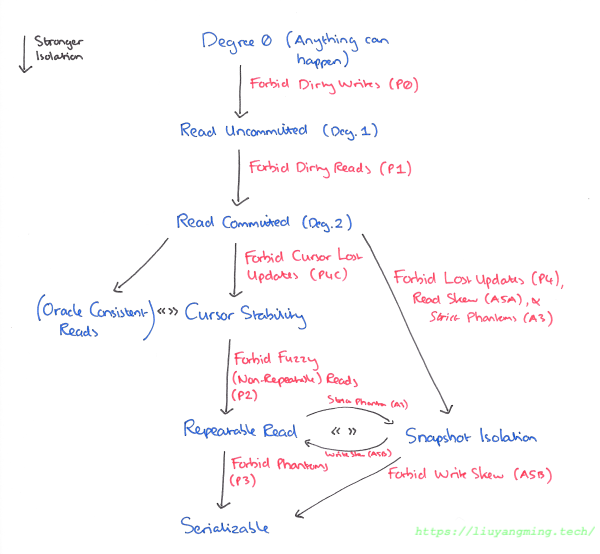
另外,由于大部分数据库实现了MVCC的并发控制,因此也产生了Lock机制下没有的并发异常,如下三种:
Lost Update (ww-conflict)
T1、T2对同一表的同一行的同一列进行更新;一个将另一个的更新覆盖。
| T1 | T2 |
|---|---|
| begin; | |
| begin; | |
| update t set val = 10 where key = ‘a’; | select * from t where key = ‘a’; |
| Commit; | update t set val = 40 where key = ‘a’; |
| Commit; |
T1的更新被覆盖了。
Read Skew
T1需要统计a/b两个账目的总值;原来a=50,b=50,a/b期间会进行转账;
| T1 | T2(a转给b 25) |
|---|---|
| Begin; | |
| select val from t where name = ‘a’; (50) | |
| Begin; | |
| update t set val = 25 where name = ‘a’; | |
| update t set val = 75 where name = ‘b’; | |
| commit; | |
| select val from t where name = ‘b’; (75) | |
| Commit; |
最后T1发现总值为125,多了25,这就是Read Skew。
Write Skew
T1读取A值,赋值给B;T2读取B值,赋值给A;如果串行执行,不管谁先谁后,最后的结果都是A=B;然而,基于MVCC的RR级别,可能出现如下异常,导致只是将a和b置换了,这就是write skew:
| T1 | T2 |
|---|---|
| Begin; | |
| Begin; | |
| select val from t where name = ‘a’;(10) | |
| select val from t where name = ‘b’;(20) | |
| update t set val = 10 where name = ‘b’; | |
| update t set val = 20 where name = ‘a’; | |
| commit; | |
| commit; | |
| b = 10 | a = 20; |
并发控制的实现中,PostgreSQL和MySQL都同时采用了lock和MVCC的方式,因此在具体表现上也有所区别,这里对两个数据库进行对比了解,如下。
对比学习MySQL与PgSQL的隔离级别实现
这里只讨论SQL标准中的隔离级别。这里就不讨论读未提交,觉得没有没有意义(没想到什么场景,有人会刻意读未提交的数据)。PostgreSQL默认是RC级别,MySQL默认是RR级别;实现方式类似也有差别。
RC(Read Commit)
在PG中,开启一个事务可以请求上述四种隔离级别(SERIALIZABLE,REPEATABLE READ, READ COMMITTED , READ UNCOMMITTED); 但是RU这个级别,其实就是RC。
NOTE:在PG里一些数据类型和函数有特殊的事务行为,特别地,对一个sequence的修改,其他事务里面可见,当前事务意外终止,也不会回滚。
在RC级别中,PostgreSQL和MySQL都是基于MVCC的方式进行读写分离:
在执行某条语句的时候,获取当前可见的数据版本,PostgreSQL叫Snapshot,MySQL叫readview。该版本的数据保证都是已经提交的数据,因此不会出现脏读,满足RC的要求。
RR(Repeat Read)
和RC相同,PostgreSQL和MySQL还是采用MVCC的方式实现;但是这里PostgreSQL和MySQL都是取事务一开始的数据版本;由于在整个事务中都是使用一个数据版本,因此对于读出的数据可以实现重复读,满足RR级别。
另外,在RR级别中,PostgreSQL和MySQL都比SQL标准更加严格,不会出现幻读。但是,在MySQL的默认隔离级别RR下没有幻读,却有幻写,如下两例:
- 更新了一个readview中的旧行
--- T1 begin
mysql> start transaction;
mysql> select * from t;
+-----+--------+------+---------+------+
| a | b | c | d | e |
+-----+--------+------+---------+------+
...
| 394 | asdf | asdf | asdf | 399 |
| 395 | asdf | asdf | asdf | 400 |
| 397 | asdf | asdf | asdfasd | 402 |
+-----+------+------+---------+------+
Query OK, 0 rows affected (0.00 sec)
mysql> select * from t where a = 396;
Empty set (0.00 sec)
--- T2 begin
update t set a = 396 where e = 402;
--- T2 end
mysql> update t set b = 'pwrite' where a = 396;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from t where a = 396;
+-----+--------+------+---------+------+
| a | b | c | d | e |
+-----+--------+------+---------+------+
| 396 | pwrite | asdf | asdfasd | 402 |
+-----+--------+------+---------+------+
1 row in set (0.00 sec)
mysql> commit;
Query OK, 0 rows affected (0.01 sec)
--- T1 end
- 插入了一个新行(即,不在readview的新行)
--- T1 begin
mysql> select * from t;
...
| 395 | asdf | asdf | asdf | 400 |
| 396 | pwrite | asdf | asdfasd | 402 |
| 397 | new insert | asdf | s | 403 |
| 398 | new insert | s | s | 404 |
+-----+------------+------+---------+------+
399 rows in set (0.01 sec)
--- T2 begin
mysql> insert into t(d) values (405);
--- T2 end
mysql> update t set e=405 where a = 399;
Query OK, 0 rows affected (0.00 sec)
Rows matched: 1 Changed: 0 Warnings: 0
mysql> commit;
Query OK, 0 rows affected (0.00 sec)
我们发现T1居然可以更新了一个没有见过的row,这是什么操作😹?原因是MySQL的readview只对非锁定读有效,对于事务中update/delete等操作都是基于最新commit的数据操作(这么看MySQL起的名——读视图也没错,但是行为有点奇怪)。
而在PostgreSQL中,更新数据页是基于snapshot进行,但是如果基于snapshot的更新与已经提交的更新冲突,那么就该事务就报错,进行回滚,
ERROR: could not serialize access due to concurrent update
如下
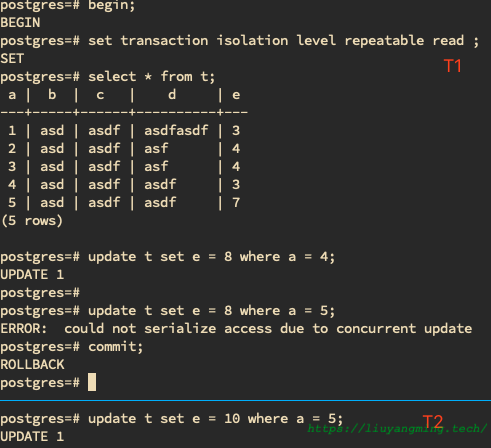
因此,对于RR级别,有如下结论:
当select-only的事务时,PostgreSQL和MySQL是没有幻读(Phantom Read)的。
在非select-only的事务中,RR级别的表现是有所不同;
MySQL/InnoDB对于没有修改的行,是RR;对于修改的行,是RC。因为,SQL标准中对此没有定义,那么也不能说违反了SQL语义。所以,InnoDB的事务修改总是基于最新的提交的数据进行修改。
InnoDB provides REPEATABLE READ for read-only SELECT, but it behaves as if you use READ COMMITTED for all write queries
PostgreSQL都是基于同一个快照更新,但是不同的快照对同一行数据进行更新有冲突了,按照first-commit-win的方式对后续事务回滚。
S(Serializable)
MySQL在S级别中,放弃使用MVCC的机制,采用Strict-2PL进行并发控制;
而PostgreSQL还是采用MVCC的机制,通过引入一个新的锁——SI-Read lock,通过该锁检查读写依赖,避免write-skew,从而实现SSI(序列化快照隔离)。该机制的实现有一个论文,比较复杂,另起一文单独讨论。