overview
PostgreSQL的planner在开源数据库中应该是代码结构相对清晰的,是个很好的学习Planner的参考资料;笔者在接触PostgreSQL的过程中,发现Planner中有一些专有的概念,理解这些概念有助于理解PostgreSQL的Planner的代码,有错误欢迎指正;应该会不定期更新,包括勘误以及增加更多的术语解释。
PgSQL Planner
Planner的目标就是找到最优的Planner,主要有两个策略,bottom-up和top-down;前者源自SystemR的经典策略,PlanTree从子节点逐步构建成整棵树,类似DP的策略;后者通常指的是cascade/volcano一类的planner,其从一个完整的tree不断变换出不同的tree,最终找到最优的那颗树,类似剪枝搜索的策略;PgSQL的经典planner属于前者;大致的执行层级如下:
plannner()
- subquery_planner()
- grouping_planner()
- make_one_rel()
- set_base_rel_pathlists()
- make_rel_from_joinlist()
- standard_join_search()
在这个优化过程中,涉及到的术语有名词和动词两类,前者是指QueryTree,或者PlanTree中的一些对象;后者指在优化过程中的一些转化操作。
术语
可以这么理解一些基本的定义,PgSQL在原始的数据Table上的Query,通过关系(Relation)代数的优化,对于每个Node生成多种Path,最后选出最优的Plan的过程;
在Query中数据载体称之为Table,即数据从哪里来的,在Plan中的数据称之为Relation,即,通过怎么样的关系运算得到的这份数据;
除了关系代数的运算外,在SQL中,还会对数据做表达式计算进行数据过滤、数据转换等操作;因此,还会有一些表达式计算相关的定义。
另外,相同的对象可能在不同的阶段中有不同的结构表示,比如QueryTree和PlanTree中对数据的某一列在Query中用ColumnRef表示,在Plan中用Var表示;这些不同的对象经常会放在同一个list中,为了了得到原来的类型,PgSQL在每个结构的第一个成员都是NodeTag的信息。Node是Planner中所有结构的基类,根据不同的分类,还有中细分的父类,比如Plan,Expr,其中定义了该细分类中的公共的成员,当然第一个成员肯定还是NodeTag。
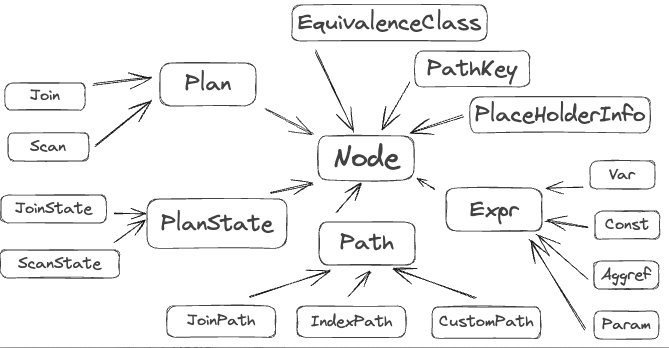
那么这里简单介绍一下常见的一些对象:
Query:parser解析SQL文本得到一个结构,代表了SQL原始的状态;PlannedStmt:planner优化Query得到一个PlannedStmt,executor可以开始执行了。PlannerInfo:planner优化过程中维护某个Query所有的优化需要的信息集合。rtable:( RangeTable ),在 Query 的From语句中出现表的集合,有不同的类型,其中每个表称为一个RTE(RangeTableEntry);注意RangeTable并不能表示表之间的连接关系,连接关系维护在jointree中,为了确保数据一直,jointree中是RangeTableRef;RelOptInfo:在planner中,通过RelOptInfo表示关系代数的各个算子节点,并维护该节点上的不同的Path;基础的Scan称为BaseRel,连接算子称为JoinRel,以及其他的UpperRel。Path:每个RelOptInfo都对应多个Path,Planner需要在多个Path中,找到最优的Path;- Parametrized Path:Path中的Restriction中有运行时才得知参数;这类Path的其中一个作用是针对于多表Join,join不管什么算法左右path都需要扫描全部的数据,只有innerpath为indexscan才能避免扫描全部的数据;如果多表join的最内层表是star-schema中的大表,那么大概率join-clause都是围绕这个大表来的,此时通过parameterized path将join-clause推到下层能够显著减少path的rowcount。
- Partial Path:PgSQL的ParallelQuery是基于data-partition来的,当ScanPath可以并行的话,就返回一个PartialPath,并标记
parallel_aware=true;PartialPath之上还可以加PartialPath,某个Node找不到PartialPath,这时就得加个Gather节点;PartialPath的Cost要算上Gather的代价,并且在一个单独的path_list中维护。
PathKey:当Path的结果有序的时候,通过PathKey得知按哪些column排序,PathKey用EC表示。Var:在表达式计算中,表示某个表的某一列;其中varno表示表在rtable中的位置,varattno表示第几列;在等价变换中这个Var可能会变化,因此这里还有varoldno和varoldattno;qual:修饰在Plan上,表示这个PlanNode返回的数据行需要满足这些qualifications;一般在Plan.qual中,但是有些特殊的qual会单独抽出来,比如Join.joinqual或者IndexScan.indexqual;RestrictInfo:修饰在Path上,来自WHERE或者JOIN ON,分别作用于BaseRel和JoinRel;在 optimizor 中,按照规则(比如是不是outer-join)下推到JoinTree中最低的RelOptInfo上。被下推的restriction的is_pushed_down标记为true;和pushdown对应的,由于outerjoin的特性,有些restriction推后执行,这些的outerjoin_delayed被标记为true。EquivalenceClass:(EC)假如where条件中有Var_a = Var_b,那么Var_a和Var_b在当前plan中就是等价的,这两个Var就可以放在同一个EC中;基于EC的性质可以对表达式进行等价变换。- Partitionwise Join:多个分区表之间的equal-Join,如果Joinkey都是partition-key,那么父表的join可以下推到各个子表进行。
- SubLink/SubSelect/SubPlan/SubQuery:一般查询只有一个Select,当Select嵌套Select时,内部的Select就称为subselect,subselect位于expression中就称为sublink,位于rangetable中就称为subquery;不管sublink还是subquery,这都是在planner阶段的称谓;在executor阶段,称为subplan。
大致过程
在PgSQL中,一个SQL可能对于多个subquery生成多个PlanTree;subquery_planner处理每个subquery,处理过程主要包含四个过程:
- Preprocess
- 对Query做一些等价变换,有些操作之间有些先后依赖关系,会在特定的顺序下执行。
- 计算标量(scalar)表达式;
- Join Tree
- 根据
from_collapse_limit,上拉SubQuery; - 根据qual是否是strict的,将外连接消除;
- 以左外连接为例,右侧需要补null,成为nullable-side;当条件使得nullable-size中的null在结果中不可能出现,这样的条件就是严格的。
- 将
in/exist转换为 semi-join;识别出anti-join;
- 根据
- Flatten
- 简单的函数;
- 简单的视图;
union all;
- 在转换好的Query上,收集Planner需要的信息;
- 确定Var需要在Tree中生命周期;
- 构建 EC;
- 收集join order restriction;
- 对Query做一些等价变换,有些操作之间有些先后依赖关系,会在特定的顺序下执行。
- BaseRel/JoinRel Path:
- Scan虽然会找到cost最便宜的path,但是会考虑
OrderBy语句,生成带PathKey的Path,或者考虑并行生成PartialPath。 - Join-Order-Search 是Planner的核心操作,是最耗时的部分;在PgSQL中,超过一定数量的表就不走DP了,直接fallback到”GEQO“的方式;通过交换子joinrel的顺序,找到最终的joinrelorder,但是有些情况下,不能交换,比如OuterJoin不能随意交换。
- 每个
RelOptInfo对于每个有用的SortOrder会保留一个cheapestpath。 - 在构建BaseRel的Path以及JoinRel的Path的时候,会基于得到的EC集合,取得一个qual,尽管这个qual并不是用户一开始写的;这样,在探索jointree的时候,可能就会避免生成一个笛卡尔积的joinnode;以及,在scan的时候,会多出一些restriction;
- Scan虽然会找到cost最便宜的path,但是会考虑
- UpperRel Path:处理Scan和Join之外的算子的Path,每种算子的Path都是放在
RelOptInfo中,这里的Rel就是UpperRel。 - PostProcess:Path转换为Executor的Plan,以及一些其他的整理工作,比如
- 移除不需要的Node。
- 标记
OUTER_VAR或者INNER_VAR。