以下是PgSQL和MySQL两个数据库在文档上关于数据缓存区的推荐配置介绍:
MySQL/InnoDB:
默认128MB;
A larger buffer pool requires less disk I/O to access the same table data more than once. On a dedicated database server, you might set the buffer pool size to 80% of the machine’s physical memory size.
PostgreSQL
默认128MB;
If you have a dedicated database server with 1GB or more of RAM, a reasonable starting value for
shared_buffersis 25% of the memory in your system. There are some workloads where even larger settings forshared_buffersare effective, but because PostgreSQL also relies on the operating system cache, it is unlikely that an allocation of more than 40% of RAM toshared_bufferswill work better than a smaller amount.
总结就是,PostgreSQL推荐设置是25%~40%的内存;MySQL推荐设置是80%;那么是什么造成这两个的不同呢?
在PostgreSQL的文档中,关于这个问题有如下的描述:
- “PostgreSQL also relies on the operating system cache”
- “Larger settings for shared_buffers usually require a corresponding increase in max_wal_size, in order to spread out the process of writing large quantities of new or changed data over a longer period of time. “
可以这么理解:
- Kernel cache(page cache)可以看做是多进程架构的应用系统的一种数据共享的方式
- 由于PostgreSQL对shared_buffers采用的是buffer IO,那么更大的shared_buffer需要在checkpoint时writeback更多脏页,以及需要更多对应这也脏页的日志空间。
了解到这基本就可以了,但是本文希望能更全面深入的了解这个问题(但仅代表基于此刻作者的知识结构的个人观点)。本文包括两个方面:
- PostgreSQL的double buffer问题
- PostgreSQL的write back机制
PostgreSQL的double buffer
在了解PostgreSQL的double buffer问题之前,先了解一下我们常用的服务器操作系统——Linux的文件读写缓存。
Linux File IO buffers
我们要将数据库的数据写入到磁盘文件中,要经历图中的几层缓存;
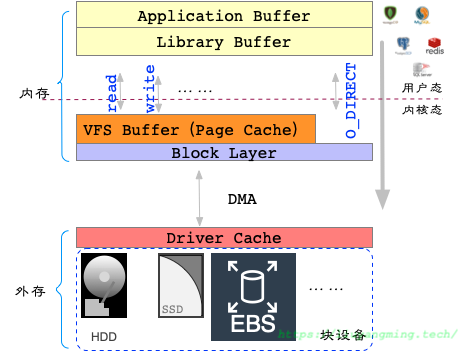
IO就是内存和外存之间的数据传输。在数据库场景中,我们认为外存是一些块设备,目前我们有很多类型的块设备,比如HDD,SSD以及一些云厂商的EBS服务,在接口上基本都一样,不需要我们考虑这里的区别。
在内存中,就是用户态和内核态;PostgreSQL位于用户态,在进行读写的时候,通过system call,将数据拷贝到内核态;另外,也有可能是通过Library间接进行system call。
在内核态中,这里只考虑两层结构:VFS和BLOCKIO层。当我们调用write将数据写出时,首先会写入到page cache中(前提是没有打开O_DIRECT,后面会详细讨论)。最后,操作系统会周期性的清理Page cache就是将Kernel Buffer中的数据写到磁盘中,或者我们对文件调用fsync,那么才最终落盘。
通过DMA的机制写盘,不占用系统CPU资源。
了解了上述大致过程,那么还是不了解什么造成的MySQL和PostgreSQL的不同,下面我们详细讨论一下文件读写的API。
文件读写API
在Linux下编程,我们可以有很多种方式操作文件,下面对各个接口进行了梳理:
- System call
| Operation | Function(s) |
|---|---|
| Open | open(), creat() |
| Write | write(), aio_write(), pwrite(), pwritev() |
| Sync | fsync(), sync(),fdatasync() |
| Close | close() |
这部分是VFS的system call,会陷入内核态;其中write:只保证数据从应用地址空间拷贝到内核地址空间,即page cache,只有fsync才保证将数据和元数据都实实在在地落盘了(fdatasync只同步数据部分,这里涉及到file integrity和data integrity,可以参考Linux的手册)。
注意
当open的时候如果加上了O_SYNC参数,那么write调用就等价于write+fsync;
当open加上O_DIRECT参数时,write的时候只会绕过kernel buffer,不会sync,但是需要要求写的时候要对齐写,比如对齐512或者4k;
- Library
| Operation | Function(s) |
|---|---|
| Open | fopen(), fdopen(), freopen() |
| Write | fwrite(), fputc(), fputs(), putc(), putchar(), puts() |
| Sync | fflush() |
| Close | fclose() |
这部分是C library的IO流式读写,对底层系统调用进行了封装;如果采用这种方式操作文件,那么fwrite的时候,可能数据还是留在用户态,这优化了频繁陷入内核态的上下文切换的代价。
- mmap
| Operation | Function(s) |
|---|---|
| Open | open(), creat() |
| Map | mmap() |
| Write | memcpy(), memmove(), read() |
| Sync | msync() |
| Unmap | munmap() |
| Close | close() |
mmap将外存的文件块映射到内存中,可以利用OS的页面管理(虚拟空间映射,页面缓存与自动刷出,页面对齐等),一些轻量级的存储引擎直接利用mmap,而不是自己实现缓冲区管理,比如BlotDB;
注意mmap同样会占用进程页表,进而可能有TLB miss的代价。
- Zero-copy
| Operation | Function(s) |
|---|---|
| Transferto | sendfile() |
上述文件读写方式,适用于对单个文件的多次频繁IO;而当我们需要将一个大文件传输到另一个大文件中时,如果采用read+write的方式,那么会和下图类似,频繁的在用户态和内核态之间拷贝数据。
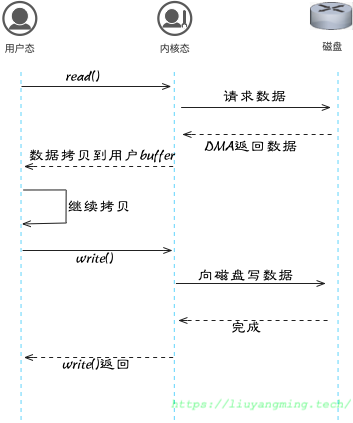
这时可以考虑使用sendfile。sendfile不需要内核态和用户态之间的数据拷贝,但是DMA需要在内核中需要维护一个连续的buffer用来传输数据。

- Linux AIO
AIO需要文件按照O_DIRECT的方式打开,AIO的接口有两种:
- Linux本身的系统调用: io_submit(2),io_setup(2), io_cancel(2), io_destroy(2), io_getevents(2)),
- POSIX类型的glibc接口:aio_cancel(3),aio_error(3), aio_init(3), aio_read(3), aio_return(3), aio_write(3), lio_listio
具体的使用方式,本文暂不讨论。
或者可以只用非阻塞的方式(O_NONBLOCK)打开文件,然后通过epoll进行多路复用读写
PostgreSQL的文件读写
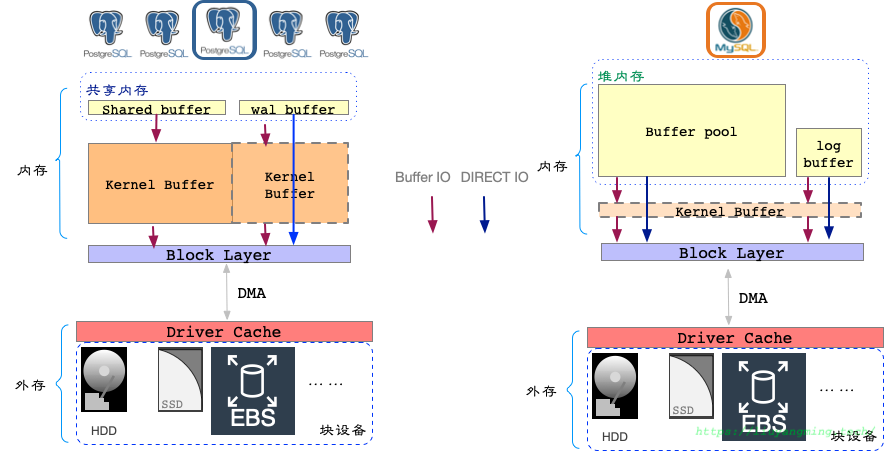
讨论数据的文件读写,主要针对两类数据:数据页和日志记录。作为对比,这里罗列了一下MySQL的相关机制;从图中可以看出,PostgreSQL的wal根据配置的不同,可能是direct io也可能是bufferio;但是shared_buffers中只有一种方式,就是buffer io。
而在mysql中,数据页和redo日志都是可以通过不同的配置,选择direct io和buffer io;但是一般配置为使用direct io;因为direct io相对buffer io来说高效些,并且DirectIO不会污染page cache,这对于pg依赖page cache作为二级缓存的db,避免了无效的cache占用。
那么为什么PostgreSQL采用buffer io呢?这里是我自己的观点。
软件系统和艺术作品类似,诞生都是有一定的历史原因的。PostgreSQL是诞生在实验室中,主要为了研究数据库内核原理,那么使用buffer io能够减少IO栈的代码开发,进而能够减少额外的debug。这样,研究人员能够更加专注在数据库内核原理的研究中,因此PostgreSQL才会有相当丰富的SQL语法、丰富的执行算法、以及优秀的基于代价的执行优化器等等功能。可以称其为一个全栈的数据库,基于其优秀的扩展性,几乎可以解决中小型公司的大部分业务场景。
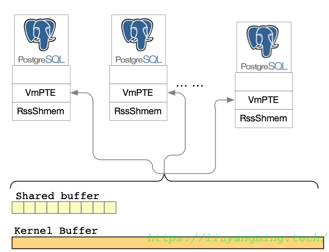
另外,PostgreSQL采用多进程的并发机制,那么多进程和多线程对内存的使用方式上存在区别,同样也是一个原因,page cache可以看做多进程之间的一种数据共享方式,关于这个这里有个小例子,如下图:

在流复制中,通过buffer io,那么wal sender可以从page cache读取wal,减少了物理读的次数。
double buffer
由于PostgreSQL采用的是buffer io,那么我们可以换一个角度看PostgreSQL的内存。可以看做是整个内存空间的一个两级缓存,但是PostgreSQL对第一级有完全的控制权。
由于内存中的两级缓存存在,那么shared_buffers中的数据页会在内存中存在两份,因此,当我们将shared_buffer配置为推荐配置的最大值40%时,其实我们已经用了80%的内存空间。这就可以理解为什么PostgreSQL推荐最大是40%。
基于这样的角度,那么我在配置shared_buffer会考虑以下几个点:
- 利用pg_buffercache判断数据库工作集和shared_buffers的关系,在下次启动时适当增减;(clockswap置换算法的count是否为5)
- 注意进程的PTE(page table entry)和max_connections,考虑TLB miss的问题**
关闭AnonHugePages,打开Linux的hugePage**,(cat /proc/meminfo grep -i huge) - 注意给其他后台进程留下空间;
这里每个点都值得深入讨论,这里就不扩展了。那么回到一开始的问题,为什么PostgreSQL和MySQL设置的不同呢?
数据库要保证数据的写入,不管是写入的时间还是写入的位置,完全在自己的掌控之中。BufferPool在DB中,可以作为读cache和写buffer,减少物理读的次数,也减少物理写的次数。但是,最终BufferPool中的数据还是要落盘的,那么落盘时的操作就是调用上述的API。
因此,造成配置的差异原因可能就是两者使用API的方式不同,其区别在于是否要留一大部分Kernel Buffer;在MySQL/InnoDB中,我们可以通过参数innodb_flush_method,决定data和log是否使用O_DIRECT(绕过Kernel Buffer)和O_SYNC;而在PostgreSQL中,我们只有通过wal_sync_method和fsync选择是否O_SYNC,没有对O_DIRECT进行选择的入口。
找了下资料,发现PostgreSQL目前的存储引擎似乎就没打算用direct IO?那么,可以期待下Zheap的引擎哈

另外,MySQL是多线程架构,bufferPool就是进程堆内空间,而且可以有多个bufferpool,那么可以尽量多将内存留给自己用,这样就会将更多的热点数据放在内存中处理,得到很好的性能,这就很直观了。
PostgreSQL的write back机制
数据回写是指从buffer pool向磁盘中写数据的过程,首先回顾以下BufferPool的结构。
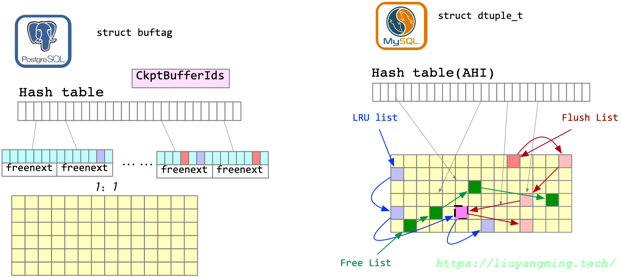
作为对比,这里还是列出MySQL的buffer pool,直观上来看,两者都是由一个hash表和一个page池。hash表就是用来定位page的地址;另外,还需要一些结构来存储page的状态,在PostgreSQL和page一一对应的有一个描述符层,其中存储了各个page的状态标志;在MySQL中,同样有一个结构存储各个page的状态,另外通过几个List来维护了脏页的list。
对于buffer pool的回写,主要涉及两个系统调用write()和fsync(),并且需要保证脏页回写的平滑和有序。平滑为了减少对业务的影响,有序是为了正常的推进checkpoint lsn。
Write()的演进

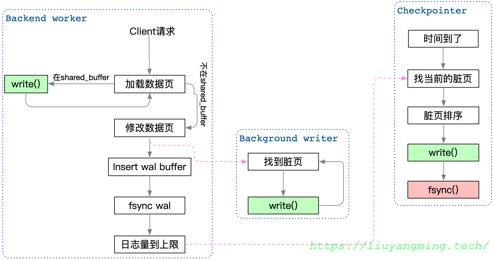
首先看一下在PostgreSQL中的write()调用,一开始只有一个backend worker进行write,负责将自己的脏页刷盘。在8.0中,拆除一个bg writer,专门负责刷脏。这样,backend worker只需要操作buffer pool中的页即可,除非bg writer写的慢了,才会自己进行write。
然后,在9.2中,bg writer中拆出checkpointer,复制checkpoint相关的逻辑,bg writer只需要write,由checkpoint进行fsync,保证checkpoint lsn之前的数据页完全落盘。
那么在目前我们用的版本中,数据的回写就是由着三个进程负责的:
可以看出来,在整个回写的逻辑中只有checkpointer在进行fsync。那么这个点可能会造成IO阻塞。问题来了,如何保障平滑呢?
首先可以通过配置Linux的writeback参数,通过时间或者百分比触发。这已经足够可以用了,但是存在一个弊端,就是这个配置是全局的,有些操作是不需要fsync的,比如临时表。因此,在9.6中,利用sync_file_range()调用,进行了更加细粒度的优化。
相比于费用fsync是在整个文件级别上的刷盘,sync_file_range可以将文件的一部分刷盘;并且,通过引入对应三个进程的三个参数,可以分别根据每个write()的量,来提前sync。这样,能够更加针对性的细粒度的减少checkpoint最后fsync的IO量。
然后,再重新回顾以下checkpoint的流程:
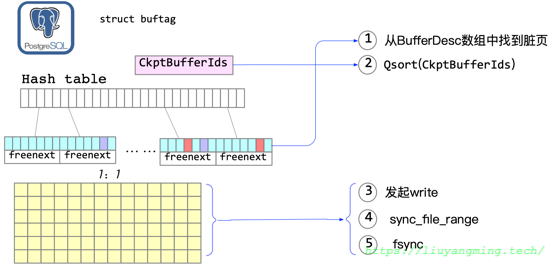
- 从描述符层,找到脏页
- 在CkptBufferIds数组中,对脏页进行排序(随机IO变顺序IO)
- 对脏页进行
write - 到达checkpointer_flush_after,进行
sync_file_range - 最后
fsync
到此,在整个shared_buffers到diskfile的数据闭环中应该都结束了;还剩一个小问题,fsync落盘一定成功吗?
fsync的语义
现在块设备的类型比之前多的多了,但是数据页的落盘还是存在落盘失败的可能。那么,肯定是会产生块IO错误,只不过出现的很少。那么在PostgreSQL的fsync失败后,如何进行处理呢。这里画了CHECKPOINT前后一个时序图,阐述一些这块的逻辑:
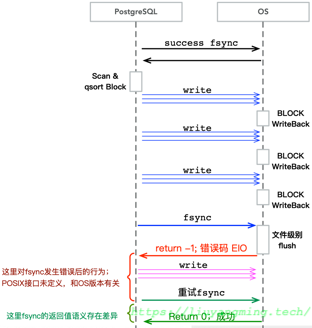
黑色箭头表示上次CHECKPOINT的fsync成功了,PostgreSQL开始进行下一次spread CHECKPOINT。首先,进行了多次write,最后调用fsync,但是返回失败。那么PostgreSQL选择重试,重试返回成功。
那么此时PostgreSQL认为“all write since last success fsync has success”,即,蓝色write和红色write都成功落盘了(两次fsync之间,可能会调用write)。
但是这个语义理解数不准备的,因为POSIX接口对于fsync返回失败后的处理方式没有定义。那么,在不同的操作系统以及同一操作系统的不同版本上可能都有出入;正确的理解应该是“all write since last fsync has success”,即,重试的fsync返回成功只能保证红色的write落盘成功,至于之前的write是否成功是未知的,因此磁盘中可能因此出现不一致的数据块。
这个问题在小版本中修复了,如下:
PostgreSQL 11 (11.2)
PostgreSQL 10 (10.7)
PostgreSQL 9.6 (9.6.12)
PostgreSQL 9.5 (9.5.16)
PostgreSQL 9.4 (9.4.21)
我们在使用PostgreSQL的过程中,应该及时升级小版本,避免采坑。另外,修复此问题的同时引入了一个新的错误处理的参数data_sync_retry。如果你能确保你的OS和存储设备不存在以上问题,那么通过data_sync_retry跳过强制crash,否则就要报PANIC级别错误,然后crash recovery。