经典的面向事务的存储系统,通常基于ARIES(Algorithms for Recovery and Isolation Exploiting Semantics)设计日志系统来保证持久性和原子性;其日志分为两种REDO和UNDO,但并不是每个数据库系统两个日志都有,这取决于BufferManager的Steal/Force策略:
- Force:确保每次事务commit所修改的数据都落盘了,才返回成功;
- 如果不满足,则需要Redo Log;
- No Steal:未提交的数据不能覆盖磁盘中已经提交的数据
- 如果可覆盖,则需要Undo Log;
我们知道PostgreSQL的HeapPage中的新旧版本同时存在,即不覆盖写,因此PostgreSQL中Undo Log(相对应的InnoDB中,就不一样了,其Btree是覆盖写);在PostgreSQL中只有一种REDO日志,也叫做WAL,即Write Ahead Log。
1. WAL里有什么
wal是一种redo日志,记录了数据的历史操作,但不只是操作记录(MySQL的binlog可以只记操作);
Undo日志记录某数据被修改前的值,可以用来在事务失败时进行rollback;以及在多版本控制中,用来构建历史数据。在PostgreSQL中没有专门的Undo日志,其旧版本的数据也是放在堆表中。
1.1 WAL在事务处理中的角色
Write Ahead Log,顾名思义就是在提前写的日志;那么,在PostgreSQL中,当执行一个事务时:
- 首先在CLOG中记录
in progress状态; - DML会在操作datapage之前,在WAL buffer中先写一条修改的logrecord,得到当前的lsn;
- 修改数据页,更新数据页的lsn;
- 提交事务(提交的操作见第三节);
- 将CLOG中的事务状态改为COMMITED
CLOG
Commit Log,记录各个事务提交状态,位于pg_xact中;同时在shared buffer中,有相应的事务状态缓存区。
1.2 wal record
通过pg_waldump可以看到wal中的信息,每一条记录对应一个资源管理器(rmgr:resourece manager)和相应资源上的操作;比如通过下面简单的命令,找到了一个COMMIT的记录,表示tid=25413的事务成功提交了。
$ pg_waldump --start 2/783D9D50 000000010000000200000078 -r Transaction
rmgr: Transaction
len (rec/tot): 46/ 46,
tx: 25413,
lsn: 2/783D9D50,
prev 2/783D9D18,
desc: COMMIT 2018-08-18 15:59:46.682666 CST
在源码的backend/access/rmgrdesc下,可以看到各个资源管理器的描述文件,这些RMGR代表着PostgreSQL里每个事务对各个存储的对象操作,恢复时根据logrecord的类型调用相应资源的回调函数进行数据恢复;比如Heap就是堆表的操作,以及各种索引等。
$ pg_waldump --rmgr=list
XLOG
Standby
Heap2
Heap
Btree
Hash
Gin
Gist
Sequence
...
1.3 事务的提交
理论上,每次commit的时候都是需要等wal record buffer刷盘后,才返回成功。而实际上当commit时,具体的行为有很多种,PostgreSQL中由synchronous_commit和synchronous_standby_names参数决定,如下图:
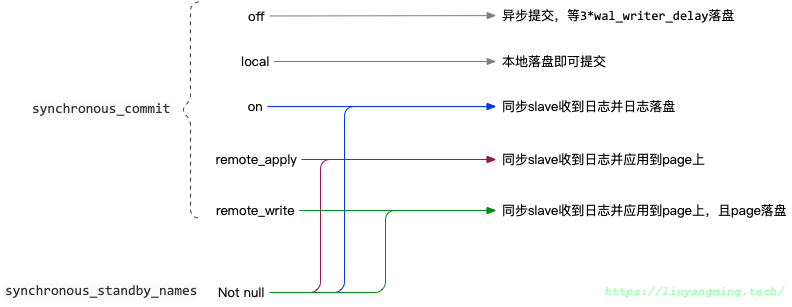
关闭synchronous_commit,不会导致数据不一致性,顶多会丢掉几个commit的事务,但是数据库中的数据是一致的。而关闭fsync,数据的落盘就没有保证了,如果你关了fsync,那么连full_page_write也一起关了得了。
所以想提高性能,可以考虑关闭synchronous_commit(最好还是别关)。
值得注意的是,synchronous_commit可以在任何地方设置,甚至可以同一个应用控制不同事务的提交级别。
2. WAL能干什么
WAL主要用来做crash&recovery,另外在PostgreSQL中还基于WAL进行主从同步。
2.1 普通恢复
在数据库中,日志记录的类型可以分为三种:logical,physical,physilogical。PostgreSQL的wal record属于physilogical(InnoDB的redo log record也是同样性质),physilogical是物理页上的逻辑变更,相比于physical更加灵活,占用空间小,但是必须在一个有效的页上进行恢复,因此PostgreSQL和InnoDB等都对页的部分写有相应的处理方式(full_page_write和double write buffer)。
full_page_write会在WAL中写一个特殊的日志记录:backup block,恢复的时候会做区分。另外,重启DB的时候进行恢复时,还有一个问题——从哪个点开始恢复的? 在PostgreSQL中是从REDOpoint开始,即最近一次成功的checkpoint开始的时候写入checkpoint record的位置:
$ pg_waldump --start 2/783D9D50 000000010000000200000078 -r XLOG
rmgr: XLOG
len (rec/tot): 106/ 106,
tx: 0,
lsn: 2/78499528, prev 2/784994F0,
desc: CHECKPOINT_ONLINE redo 2/784994F0;
tli 1; prev tli 1; fpw true; xid 0:25416; oid 33250; multi 2; offset 3; oldest xid 548 in DB 1; oldest multi 1 in DB 1; oldest/newest commit timestamp xid: 0/0; oldest running xid 25416; online
PostgreSQL恢复的一般流程如下:
当PostgreSQL启动的时候,检查pg_control文件中的state字段,如果是
in production,表示非正常结束; PostgreSQL进入恢复默认;从pg_control找到最新的checkpoint,从WAL相应的checkpoint位置开始恢复,如果该checkpoint损坏,从pg_control读取prior checkpoint(PG11中将不会存储这个信息);
开始恢复;
PostgreSQL的每个页头部上有最后更新的lsn;
PostgreSQL比较WAL记录的lsn和数据页的lsn:如果WAL记录的lsn大,那么将这个record重放(redo),并修改页的lsn;否则,不做操作
重放的时候按照rmgr对应的资源管理器(’Standby,Transaction,Sequence,Btree,Heap’)进行对应的操作;
比如下例,对Heap资源进行恢复操作,就是在关系表1663/13451/16498的相应偏移上插入一条记录,可见这是物理数据上的逻辑日志。
rmgr: Heap len (rec/tot): 175/ 175, tx: 24388, lsn: 2/5B002070, prev 2/5B0013B8, desc: INSERT off 46, blkref #0: rel 1663/13451/16498 blk 42
2.2 有整页镜像的恢复
打开full_page_write选项后,在checkpoint后,对页面的第一次修改会将整个页复制到wal记录中,那么恢复的时候,当记录是整页镜像时,直接用整页镜像覆盖这个page,并更新这个page的lsn;
这个整页镜像叫做backup block;non-backup block中的redo操作不是幂等的,所以要按照xlog的lsn大小,顺序恢复;backup block直接覆盖即可。
3. 怎么管理WAL
3.1 事务日志的分段存储
事务日志可以非常大,但是如果在一个文件里不方便管理,我们将事务日志切分为16Mb的segment;每个segment是一个24位的16进制数字,前八位是timelineid,中间8位和最后8位可以看做是 一个256进制的两位数:当最后8位满0xFF进1的时候,中间8位+1;以此类推
通过pg_walfile_name函数,可以传入一个lsn值,得到该lsn对应的record在哪个wal中;
# select pg_walfile_name('2/783D9D50'); -[ RECORD 1 ]---+------------------------- pg_walfile_name | 000000010000000200000078
一个16Mb的wal段,内部切分为8k大小的页(日志文件是切分为512Mb的block);第一个页有一个整段的头部数据,其他每个页也有相应页的定义;
3.2 Wal Writer进程
这个服务进程间歇的运行,将wal buffer刷新到磁盘上,主要是防止同时提交太多,导致磁盘IO过载;
3.3 Checkpointer进程
当出现以下三种情况下时,checkpointer进程启动,进行CHECKPOINT操作:
时间到了
checkpoint_timeout: 距离上次checkpoint过去了这些时间,默认5分钟- wal日志数量到了
- .4之前的配置了checkpoint_segment参数,默认是3,消费了这些wal segment,就会触发checkpoint
- 9.5之后,总的walfile超过了
max_wal_size;默认64个file 1GB
- 主动执行
- PostgreSQL在smart或者fast模式stop,start_basebackup
- superuser,手动执行,checkpoint
3.4 Wal段文件管理
3.4.1 何时切换wal段文件
只要每次产生了一个新的wal,就执行archive_commond:
- 满了
- pg_switch_xlog
- archive_mode = on且archive_timeout
3.4.2 如何安全地删除wal
如果想要删除wal日志,要么让pg在CHECKPOINT的时候自己删除,或者使用pg_archivecleanup。除了以下三种情况,pg会自动清除不再需要的wal日志:
archive_mond=on,但是archive_commandfailed,这样pg会一直保留wal日志,直到重试成功。wal_keep_segments需要保留一定的数据。- 9.4之后,可能会因为replication slot保留;
如果都不符合上述情况,我们想要清理wal日志,可以通过执行CHECKPOINT来清理当前不需要的wal。
在一些非寻常情况下,可能需要pg_archivecleanup命令,比如由于wal归档失败导致的wal堆积引起的磁盘空间溢出。你可能使用这个命令来清理归档wal日志,但是永远不要手动删除wal段;
3.4.3 从归档wal中恢复
可以手动的将wal从归档复制回pg_xlog/pg_wal中,或者创建一个recovery.conf其中配置好restore_command来做这件事。