什么是checkpoint
checkpoint会将某个时间点前的全部脏数据刷新到磁盘,以实现数据的一致性与完整性。保证数据已经同步到磁盘中了,这样可以:
- 回收wal日志,节省磁盘空间
- 恢复的时候可以快一些。
数据库的写入,是先写wal,后checkpoint定期刷盘,用户请求只需要等待wal刷盘完成即可(至于是刷的主的盘,还是从的盘就由同步提交参数控制了);日志是顺序写,数据是随机的,提高了IO效率;当数据是GB的,wal是TB的;保存所有的wal是不现实的;所以通过checkpoint,保证在wal的某个位置之前的所有变更,都已经写到磁盘中了;减少recovery时间,进而之前的wal数据,理论上就可以删了。
PostgreSQL的checkpoint详细操作
在checkpoint进程启动的时候,在内存中记录一个REDO点;REDO点就是PostgreSQL的恢复进程开始恢复XLOG(WAL)的位置。
关于这个checkpoint的xlog record写入到wal buffer中
$ pg_waldump 000000010000000200000062 | grep -E -v 'Standby|Transaction|Sequence|Btree|Heap' | head -n 1 rmgr: XLOG len (rec/tot): 106/ 106, tx: 0, lsn: 2/620655F0, prev 2/620655B8, desc: CHECKPOINT_ONLINE redo 2/620655B8; tli 1; prev tli 1; fpw true; xid 0:24649; oid 33250; multi 2; offset 3; oldest xid 548 in DB 1; oldest multi 1 in DB 1; oldest/newest commit timestamp xid: 0/0; oldest running xid 24649; online将所有的shard Memory刷新到存储中(包括clog);
shard buffer 中的dirty page逐渐地刷新到磁盘中
更新pg_control文件,其中有checkpoint的lsn信息(后期恢复可以从这个文件读取checkpoint的lsn)
在top中,按照shr排序,可以发现checkpointer总是和startup进程有相同大小的shard memory,checkpointer作为startup进程的子进程,可共享同样大小的shr(<=shared buffer);
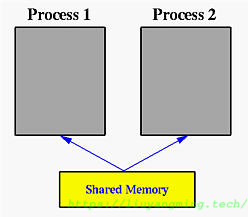
什么是shr?
在fork()出子进程后,为了安全性,parent和child有独立的地址空间。而在UNIX System V类的os中( Linux, SunOS 和 Solaris),提供了基于shr的进程间通信的特性。即,通过将共同的shared memory ID标识的shr,挂载到自己的地址空间中,实现两个进程贡献一块内存,如图;
PostgreSQL11移除secondary checkpoint
https://paquier.xyz/postgresql-2/postgres-11-secondary-checkpoint/
何时触发
- 超级用户(其他用户不可)执行CHECKPOINT命令
- 间接执行:pg_start_backup/create database/pg_ctl stop/restart…
- 到达配置中配置的执行checkpoint的间隔时间
- 到达配置中配置的wal数量限制(checkpoint_segments)
- 数据库recovery完成后
观察 Spread checkpoint的状态
pg_stat_bgwriter
PostgreSQL中的background writer是用来执行checkpoint的,其中checkpoints_timed记录了周期性执行的checkpoint的次数;checkpoint_req记录的是主动请求的checkpoint的次数;
View "pg_catalog.pg_stat_bgwriter"
Column | Type | Collation | Nullable | Default
-----------------------+--------------------------+-----------+----------+---------
checkpoints_timed | bigint | | |
checkpoints_req | bigint | | |
checkpoint_write_time | double precision | | |
checkpoint_sync_time | double precision | | |
buffers_checkpoint | bigint | | |
buffers_clean | bigint | | |
maxwritten_clean | bigint | | |
buffers_backend | bigint | | |
buffers_backend_fsync | bigint | | |
buffers_alloc | bigint | | |
stats_reset | timestamp with time zone | | |
checkpoint周期的配置
目标是,checkpoint以不影响用户使用的频率执行;
time和size的限制
- checkpoint_timeout = 5min
- max_wal_size = 1GB (9.5之前叫:checkpoint_segments)
NOTE:
max_wal_size不是一个强制的限制
取决于需要的恢复时间,选择一个合理的checkpoint_timeout值;一般来说,默认的5分钟有点低,取30min到1h比较常见,9.6之后最大值可以设置1天;由于full_page_writes=on,太小的值可能导致写放大。
full_page_writes
系统崩溃时,写盘的进程对page的写入可能只完成了一部分。系统崩溃后,我们基于checkpoint+wal进行恢复,可以恢复到一个某一时刻的一致性的状态;这一恢复策略的前提是checkpoint点确保db磁盘上的全备是一致的,后续wal确保在data之前写入磁盘。
为了避免数据页的部分写,打开full_page_writes=on后,当启动checkpoint后,页面上发生第一次修改时,将页面整体写入到wal中;这就保证了wal开始恢复的时候是一致性的状态。
当启动checkpoint时,在wal中会记一个checkpoint记录,表示checkpoint开始了(但并不能从这个点开始恢复,因为这只是个开始);之后checkpointer开始按部就班的将数据页同步到disk中,如果checkpoint后数据不进行写入,那么为了不影响读的性能,就这么spread的方式完成checkpoint即可,不会占用太多disk带宽。但是checkpoint之后,数据还是会写入(总不能开了checkpoint,就对整个盘加了写锁吧),在checkpoint点处的老的且一致性的同步到磁盘前,新的数据就覆盖了buffer,这起点的位置就模糊了并且这时起点的一致性还是靠checkpoint提供,而checkpointer和bgwriter在系统崩溃时可能会失败,这又回到开始的问题了。那么就会问了,wal writer不会有问题么?
为了避免wal页的部分写,每个wal record包含一个CRC校验,来检查数据的正确性。每个WAL page 包含一个magic number,读取每个页的时候来校验正确性。
最后,当checkpoint_timeout太小时,常常写全页的wal,开销自然大了,应做好调整。
设置参数的方法
把max_wal_size设置几乎不可能达到的足够大
使用
pg_current_xlog_insert_location()postgres=# SELECT pg_current_xlog_insert_location(); pg_current_xlog_insert_location --------------------------------- 3D/B4020A58 (1 row) ... after 5 minutes ... postgres=# SELECT pg_current_xlog_insert_location(); pg_current_xlog_insert_location --------------------------------- 3E/2203E0F8 (1 row) postgres=# SELECT pg_xlog_location_diff('3E/2203E0F8', '3D/B4020A58'); pg_xlog_location_diff ----------------------- 1845614240 (1 row)5分钟产生了1.8g的wal日志
log_checkpoints=on
从日志里看checkpoint的统计信息
select * from pg_stat_bgwriter
总结
在PG中,记录的更改是先记录到wal日志中的;除非shared_buffer满了,才会将脏页写出去;这意味着当系统crash了,启动的时候需要重做wal日志;
在checkpoint期间,db需要执行以下三个步骤;
- 确认shared buffer中,所有的脏页
- 将所有的脏页写盘(或者在文件系统缓存中)
- fsync() to disk
本来PG是一下做完的,但是这样会使IO夯住,影响用户使用。在8.3之后,引入了spread checkpoint,这给了OS时间将脏页写出去,最后的fsync就没那么耗时了;
有一些OS参数控制着文件系统缓存;比如
- vm.dirty_expire_centisecs
- vm.dirty_background_bytes
- dirty_background_ratio
- dirty_background_ratio
- dirty_writeback_centisecs
在一些有超大内存的机器上,这些值的默认值很高;这导致系统倾向于一次将所有的脏页写出,这就使得spread checkpoint没有作用了。
数据库参数checkpoint_completion_target = 0.5,意味着当checkpoint_timeout等于30min的时候,在前15分钟,数据库将所有的写操作完成,之后的15分钟留给文件系统去fsync;一般不会设置成0.5, 毕竟文件系统刷新缓存也是有上面的参数限制的。通常的公式如下
(checkpoint_timeout - 2min) / checkpoint_timeout
最后,
- 大部分的checkpoint是基于时间的 checkpoint_timeout。
- 选定好时间间隔后,选择max_wal_size来估计wal大小。
- 设置checkpoint_completion_target,这样内核有足够的时间(但是不需要太多)来刷盘。
- 修改系统参数vm.dirty_background_bytes,这样OS不会将大部分的脏页一次写盘。