当数据库中并发的执行多个任务时,并发控制是维护事务的一致性(C)和隔离性(I)的机制(WAL for AD)。有三个类并发控制策略:
- 多版本并发控制(MVCC),维护数据的多个版本,通过获取数据版本快照进行事务隔离。
- 严格两阶段锁(S2PL),通过获取指定资源的锁的方式进行事务隔离;
- 乐观的并发控制(OCC),将事务的冲突延后在commit时进行判断,适用于冲突少的场景。
MVCC的是实现方式大概有两种,关键就在于将旧数据放在什么地方;
1. 将多版本的记录都存储在数据库中,垃圾收集器清理不需要的记录。比如:PostgreSQL/Firebird/Interbase ,而SQL Server将其存储在tempdb中。
2. 将最新的记录放在数据库中,通过恢复undo日志,来重建旧版本的数据。比如Oracle、MySQL(innodb)。
在标准SQL中,隔离级别有四种:RU,RC,RR,Serialize。PostgreSQL是基于MVCC实现的事务隔离称之为快照隔离SI(Snapshot Isolation)。SI不允许出现在ANSI SQL-92标准中定义的三种异常,即脏读,不可重复读和幻读。但是,SI不能实现真正的可串行化,因为它允许序列化异常,比如 Write Skew 和 Read-only Transaction Skew。
为了解决这个问题,从版本9.1开始添加了可序列化快照隔离(SSI)。 SSI可以检测序列化异常,并且可以解决由这种异常引起的冲突。因此,PostgreSQL 9.1及更高版本提供了真正的SERIALIZABLE隔离级别。
据我目前所知,SQL Server也使用SSI,Oracle仍然只使用SI。
MVCC in PostgreSQL
在基于MVCC的DML操作中,当一个行被更新,创建一个新的tuple插入到表中。老tuple保留一个指向新tuple的指针。老tuple 标记为expired,但是仍然保留在数据库中,直到被作为垃圾清理了(vacuum)。
版本号——txid
区别新老版本的依据是事务ID(xid),xid从3开始增长,0,1,2已作为特殊用途:
InvalidTransactionId = 0:表示是无效的事务ID
BootstrapTransactionId = 1:表示系统表初使化时的事务ID,比任务普通的事务ID都旧。
FrozenTransactionId = 2:冻结的事务ID,比任务普通的事务ID都旧。
txid是一个uint32类型的整数,由于32位整数可以达到理论上限(40亿容量,PostgreSQL未来可能会改成64位,可认为无限大,已经有商业版是64位的);如果数据库长时间运行,那么可能txid不够,回卷(wraparound)到3,这会有问题,因此PostgreSQL会定期回收xid(vacuum)。
那么,tuple就和xid进行绑定,每个tuple有两个额外的xid列,用来标记该tuple的生命周期,如下:
xmin:创建该tuple的事务id;xmax:删除该tuple的事务id或者对该元组加锁的事务ID,初始为null(0);
根据tuple绑定的xid和当前事务进行比较,就可以判断tuple的可见性。
txid比较
当然比较的前提是数据库没有发生txid wraparound,基于每个tuple上的txid,按照如下函数比较事务的新旧。
// src/backend/access/transam/transam.c
/*
* TransactionIdPrecedesOrEquals --- is id1 logically <= id2?
*/
bool
TransactionIdPrecedesOrEquals(TransactionId id1, TransactionId id2)
{
int32 diff;
if (!TransactionIdIsNormal(id1) || !TransactionIdIsNormal(id2))
return (id1 <= id2);
diff = (int32) (id1 - id2);
return (diff <= 0);
}
第一个判断条件
(!TransactionIdIsNormal(id1) || !TransactionIdIsNormal(id2)):如果有一个事务是特殊事务,那么特殊事务一定比普通事务旧(等价于无符号的比较);对于普通事务,在PostgreSQL中,认为同一个数据库中,有效的最旧和最新两个事务之间的年龄是最多是$2^{31}$,而不是无符号整数的最大范围$2^{32}$。那么有: \[id_1 < id_2\] \[\Leftrightarrow 0<id_2 - id_1<2^{31}\] \[\Leftrightarrow -2^{31}<id_1 - id_2<0\]
因此,可直接判断$id_1-id_2$转成有符号数是否为负数,可得到两个事务号的先后顺序。
所以,当数据库中的表的年龄差将要超过2^31次方时(即,pg_class.relfrozenxid = vacuum freeze的上限;这个上限根据配置决定);就需要回收旧的事务号,即,把旧的事务换成一个事务ID为2的特殊事务,这就是`vacuum freeze操作。
在VACUUM FREEZE中,会将行FROZEN;被FROZEN的行根据第一个判断条件比所有事务都旧,即所有事务都可见。
SnapShot
typedef struct SnapshotData
{
TransactionId xmin; /* all XID < xmin are visible to me */
TransactionId xmax; /* all XID >= xmax are invisible to me */
TransactionId *xip;
uint32 xcnt; /* # of xact ids in xip[] */
...
}
PostgreSQL中的快照记录了当时事务的状态,由三元组表示:
- 该快照获取时的最老的事务xmin;
- 该快照获取时的最新的事务xmax;
- xmin与xmax之间还未完成的xip_list;
» SELECT txid_current_snapshot();
txid_current_snapshot
-------------------------------------------------------------------------------------------------------------------------------------
38680822006:38681134130:38680822006,38681033875,38681134028,38681134029,38681134060,38681134061,38681134062,38681134063,38681134064
(1 row)
如上例意味着,获取当前快照时:最小的txid=38680822006,最大的txid=38681134130;这之间还有这些38680822006,38681033875,38681134028,38681134029,38681134060,38681134061,38681134062,38681134063,38681134064事务还没结束。
隔离性
在RC级别,事务中的每个语句执行的时候,获取一个txid_current_snapshot;其他级别在事务一开始的时候获取txid_current_snapshot。基于当前快照和pg_clog的提交记录,与元组的t_xmin/t_xmax来综合判断可见性。
另外为了提高速度,pg_clog有缓存,并且每个PostgreSQL Table有一个可见性映射表(visibility map。
| 隔离级别 | 脏读 | 不可重复读 | 幻读 | 序列化异常 |
|---|---|---|---|---|
| READ COMMITTED | N | P | P | P |
| REPEATABLE READ | N | N | N in PG; but P in ANSI SQL | P |
| SERIALIZABLE | N | N | N | N |
在PostgreSQL的RR级别中,当事务开始后,任何操作就是基于最开始的快照;因此,幻读也不会发生(幻读的发生也是当前事务能够感知到别的事务在其开始之后的更改)。
VACUUM for PostgreSQL MVCC
说起PostgreSQL的MVCC,由于PostgreSQL的实现机制,不得不提VACUUM。
事务的状态保存在clog中,表中包含两个bit的status信息(in-progress/committed/aborted)。当事务中止,PostgreSQL不做undo操作,只是简单的在clog/xact中将事务标记为aborted。因此PostgreSQL的表可能会包含aborted的事务的数据(为了避免总是查询CLOG,PostgreSQL在tuple中保存了status标记known commited/known aborted)。
简述
对于MVCC产出的脏数据以及XID回卷的问题,VACUUM进程作为数据库的维护进程,有两个主要任务:
- 清理dead tuple :expired和aborted的行以及这些行相关的索引。
- 冻结旧事务id,更新相关系统表,移除不需要的clog/xact。
vacuum和analyze是两个操作,但是vacuum命令可以加一个可选参数analyze,表示执行vacuum的时候收集一下统计信息;但是freeze不是一个单独的命令,执行vacuum不加freeze的时候,会根据数据库的年龄以及配置参数也可能会执行一些冻结操作。
我们可以手动或者自动的进行VACUUM操作,VACUUM 操作会重新回收dead tuple的磁盘空间,但是不会交给OS,而是留待重用。
VACUUM FULL会把空间返回给OS,但是会有一些弊端;
- 排他的锁表,阻塞该表上的所有操作。
- 会创建一个表的副本,所以会将使用的磁盘空间加倍,如果磁盘空间不足,不要执行。
虽然可以利用定时任务周期执行VACUUM,但是周期的大小不确定,而且有可能这个周期内并没有dead tuple产生,这样就徒增CPU和IO的负载;因此,有了autovacuum,这是按需执行的;autovacuum间隔autovacuum_naptime执行一次vacuum和analyze命令;但是,为了避免autovacuum对系统的影响,如果autovacuum的代价超过了autovacuum_vacuum_cost_limit,那么就等autovacuum_vacuum_cost_delay这些时间;
autoanalyze
autovacuum 除了干回收的事,还同时统计信息;
两种模式
lazy vacuum:执行的时候,会通过可见性映射表(vm),判断page中是否有垃圾需要清理;所以在lazy mode的时候,可能不会完全冻结表中的元组。
anti-wraparound vacuum:会扫描所有的page,执行比较慢;在9.6中,visible map加了一个bit位:all-frozen,提高anti-wraparound vacuum的性能。
每个表都有一个pg_class.relfrozenxid值(整个数据库有一个pg_database.datfrozenxid,是pg_class.relfrozenxid中最小的)。通过比较三个信息:当前xid(当前所有的运行事务的xid最老的,如果只有VACUUM那么就是是vacuum事务的xid)、relfrozenxid、PostgreSQL配置的两个参数,决定VACUUM是在那种模式下工作。
- vacuum_freeze_table_age:当relfrozenxid超
vacuum_freeze_table_age时,手动执行vacuum的时候,会进行anti-wraparound vacuum。 - autovacuum_freeze_max_age:当达到
autovacuum_freeze_max_age,为了避免xid回卷,会自动进行anti-wraparound vacuum。
当进行VACUUM时,如果表中的元组的版本号超过 vacuum_freeze_min_age时,VACUUM会将其替换为FrozenTransactionId(2)。
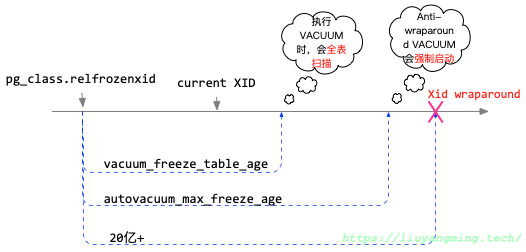
| 阶段 | 操作 |
|---|---|
current_xid<relfrozenedxid+vacuum_freeze_table_age | 如果执行VACUUM,lazy vacuum |
current_xid>relfrozenedxid+vacuum_freeze_table_age && current_xid<relfrozenedxid+autovacuum_max_freeze_age | 如果执行VACUUM,那么执行anti-wraparound vacuum |
current_xid>relfrozenedxid+vacuum_freeze_table_age | 强制执行anti-wraparound vacuum |
执行anti-wraparound vacuum过后,relfrozenxid 大概等于vacuum_freeze_min_age(精确度取决于VACUUM的时间长短)。
VACUUM的历史
从8.3开始,autovacuum默认可用,并且是多进程的架构,同时多表操作。并且可以自己决定该对哪些表进行VACUUM,这可以减少大部分的手动vacuum的工作;
在8.4中,提出了两个特性;
- 动态分配空间的free space map,这样当fsm空间不够,PG不会丢失对这些的记录;
- 添加一个visibility map,维护了堆表中哪些page只包含所有事务都可见的tuple,VACUUM可以通过判断该map,跳过部分没有脏row的page。
PostgreSQL中的锁,除了用户可见的表锁,行锁之外,还有内部的页锁。VACUUM被卡主这个问题主要是因为autovacuum等待的页锁,很长时间没有释放,这样就会导致膨胀问题。
针对VACUUM阻塞问题的优化:
在9.1中,autovacuum可以跳过当前获得不到表锁的表。
在9.2中,系统可以跳过获得不了清理锁的相应page,除非这个page包含一些必须要remove或者frozen的tuple。
在9.5中,减少了b-index保留最近访问的index page的情形,这样减少了VACUUM因为等待index scan而被卡主的case。
针对减少page访问次数的优化:
在9.3之前,在上一次VACUUM中,某个page如果没有更改,那么这次的vacuum就将其中的tuple标记为all-visible,这样,除非xid溢出,之后的VACUUM就会跳过这一个page。
在9.6中,即使xid溢出,VACUUM也可能跳过这个page。在9.6中的visibility map,增加了一个bit位,不仅记录page是不是all-visible,也记录是不是all-frozen.
VACUUM依然存在的问题
- 如何避免对index page的无谓扫描。比如,即使VACUUM发现没有dead row,依然会扫描index page,回收empty page。improve 针对这一问题有一个patch,但是对于b-index与xid溢出的处理没有处理好。
- 表中有deadrow但是很少的情况下的VACUUM;autovacuum不会被触发,而VACUUM需要全表扫描又太耗时。
- VACUUM需要好多操作,将很多操作放在一起执行是很有效率,但是一次执行需要的时间就很多,是不是可以考虑将VACUUM操作分成几小步来操作。
- 默认的基于代价的VacuumDelay设置太小了,对于大的DB,取决于autovacuum的执行速度,取决于表脏的程度。某些经常更新的表的变脏的速度快于autovacuum清理的速度,表就会膨胀。
- VACUUM无法感知系统的负载情况,只有人为的配置,在空闲的时候执行VACUUM。
VACUUM监控和调优
VACUUM发展了这么久,小型系统可以应付,大系统依然需要良好的 监控、管理、调优。
监控
- 表中dead tuple数量:
pg_stat_all_tables.n_dead_tup - dead/live比例:
(n_dead_tup / n_live_tup) - 每行的空间:
select relname,pg_class.relpages / pg_class.reltuples from pg_class where reltuples!=0; - 插件:pgstattuple
调优
清理dead tuple时,不浪费磁盘空间、预防索引膨胀、保证查询响应速度;最小化清理的影响;不要清理的太频繁,这样浪费CPU/IO资源影响性能(实际案例中,由于执行autovacuum,影响系统的pagecache,进而影响内存利用率,从而影响性能)。
1. 表的参数
控制autovacuum触发的时间;
autovacuum_vacuum_threshold=50autovacuum_vacuum_scale_factor=0.2
当pg_stat_all_tables.n_dead_tup 超过 threshold + pg_class.reltuples * scale_factor就会触发autovacuum;表膨胀超过20%就触发,threshold=50是防止一些小表被频繁的触发;
ALTER TABLE t SET (autovacuum_vacuum_scale_factor = 0.1);
ALTER TABLE t SET (autovacuum_vacuum_threshold = 10000);
2. 系统代价参数
为了不影响用户使用,不过多的占用cpu io;
清理的进程从disk中逐个的读取page(8k),判断其中有没有dead tuple,如果没有那么就不管了;如果有,就将其中的dead tuple清理掉,然后标记为dirty,最后写出去;这一过程的cost基于一下三个参数来确定,这样我们可以评估autovacuum的代价;
vacuum_cost_page_hit = 1
vacuum_cost_page_miss = 10
vacuum_cost_page_dirty = 20
如果page是从share buffer中读取的,代价为1;如果share buffer中没有,代价为10;如果被清理进程标记为dirty,代价为20;
基于以上的代价,每次autovacuum执行有一个cost的限制;如下
- autovacuum_vacuum_cost_delay = 20ms
- autovacuum_vacuum_cost_limit = 200
默认是200,执行代价总数为200的工作;每次工作完,间歇20ms;
那么实际上执行的多少工作?基于20ms的间隔,cleanup能够每秒做50轮;每轮能够做200代价;那么:
- 从shared_buffer读page,80MB/s
- 从OS(可能是磁盘)读page,8MB/s
- 4Mb/s的速度写出autovacuum标记的脏页
基于当前的硬件,这些参数都太小了,cost_limit可以设置成1000+
3. 工作进程数
PostgreSQL可以启动autovacuum_max_workers个的进程来清理不同的数据库/表;大表小表的代价不同,这样不会因为大表的工作,阻塞了小表;但是上面的cost_limit是被所有的worker共享的,所以开多个worker也不一定快。
所以,当清理进程跟不上用户活动时,提高worker数是不行的,要提高改变的cost参数;这里其实可以在单独的表上设置这两个值:
ALTER TABLE t SET (autovacuum_vacuum_cost_limit = 1000);
ALTER TABLE t SET (autovacuum_vacuum_cost_delay = 10);
这些表的清理工作的cost,不包含在全局中,单独计算。提高了一定的灵活性;但实际生产中,我们几乎不会用这个特性:
- 一般需要一个唯一的全局后台清理cost限制
- 使用多个worker,有时被一起限制,有时单独来,很难监控和分析;
VACUUM使用总结
- 不要禁用autovacuum
- 在update delete频繁的业务中,减低scale factor,这样清理进程可以及时的进行
- 在好的硬件下,提高限流阀,这样清理进程不会被中断
- 单独提高autovacuum_max_worker不行,需要和参数一起调整
- 使用alter table设置参数要慎重,这会让系统变得复杂;
引用文献