现象
系统表pg_shdescription是cluster共享的catalog(其他共享的catalog还有pg_authid等)。出现的问题如下:
postgres=# vacuum FREEZE VERBOSE pg_shdescription;
INFO: vacuuming "pg_catalog.pg_shdescription"
ERROR: found xmin 552 from before relfrozenxid 2018400456
postgres=# vacuum FREEZE VERBOSE pg_statistic;
INFO: vacuuming "pg_catalog.pg_statistic"
ERROR: found xmin 555 from before relfrozenxid 2018400456
postgres=# select relname,relfrozenxid from pg_class where relname ~ 'pg_statistic$|pg_shdescription$';
relname | relfrozenxid
------------------+--------------
pg_statistic | 2018400456
pg_shdescription | 2018400456
(2 rows)
该错误信息是说明发现了一个比表的冻结年龄更早的数据记录。
PgSQL的年龄先后判断逻辑,在函数
TransactionIdPrecedes中。通过debug,改函数确实返回1。Run till exit from #0 TransactionIdPrecedes (id1=555, id2=2018400456) at transam.c:308 0x00000000004dc72d in heap_prepare_freeze_tuple (tuple=0x2b9ece599780, relfrozenxid=2018400456, relminmxid=1, cutoff_xid=2423685768, cutoff_multi=4289967297, frz=0x1cf8e58, totally_frozen_p=0x7ffe5082dacf "") at heapam.c:6669 6669 heapam.c: No such file or directory. in heapam.c Value returned is $5 = 1 '\001'
理论上,表中不会出现比表的relfrozenxid小的年龄;因为,每次vacuum要将表中需要冻结的tuple,在t_infomask中标记为frozen,并且更新pg_class中的relfrozenxid。这是一次非正常情况,相应在代码中这个错误的err_code为ERRCODE_DATA_CORRUPTED。
之前经常在pg_authid中出现这个错误,解决的方法是将有问题的role删除,但是这里删除后需要等待一会,才能正常执行vacuum。这次出问题的表正常只有三条记录,现在有问题的记录是一个不可见的记录,无法进行删除。
问题定位
该库是pg_upgrade升级上来的,通过link的方式升级的,并且升级过后没有删除老的数据;从系统表中可以看出从12.7日,改表的vacuum就出现了异常;该时间点就是该库升级的时间点。
» SELECT last_vacuum from pg_stat_sys_tables where relname ~ 'pg_statistic$|pg_shdescription$';
last_vacuum
-------------------------------
2018-12-07 02:18:01.396058+08
2018-12-07 02:18:01.374234+08
(2 rows)
为什么有不可移除的行版本
datfrozenxid/relfrozenxid是每个表中最老的没有frozen的行版本。pg_database中的datfrozenxid是pg_class中所有relfrozenxid中最老的,
To track the age of the oldest unfrozen XIDs in a database,
VACUUMstores XID statistics in the system tablespg_classandpg_database
上述出现问题的是系统共享的表,所以所有的库的年龄都一样的大:
postgres=# select datname,datfrozenxid,age(datfrozenxid) from pg_database ;
datname | datfrozenxid | age
-----------+--------------+-----------
mydb | 2018400456 | 455335315
template0 | 2018400456 | 455335315
postgres | 2018400456 | 455335315
template1 | 2018400456 | 455335315
(4 rows)
在找问题的过程中,创建一个普通的表a,将其中三个元组删除了。
postgres=# \d a
Table "public.a"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
a | integer | | |
b | integer | | |
postgres=# table a;
a | b
---+---
1 | 1
(1 row)
postgres=# select lp , lp_off , t_xmin, t_xmax, t_field3, t_ctid, t_infomask2, t_infomask from heap_page_items(get_raw_page('a', 0));
lp | lp_off | t_xmin | t_xmax | t_field3 | t_ctid | t_infomask2 | t_infomask
----+--------+------------+------------+----------+--------+-------------+------------
1 | 8160 | 2473735754 | 0 | 0 | (0,1) | 2 | 2304
2 | 8128 | 2473735754 | 2473735755 | 0 | (0,2) | 8194 | 1280
3 | 8096 | 2473735754 | 2473735756 | 0 | (0,3) | 8194 | 1280
4 | 8064 | 2473735754 | 2473735763 | 0 | (0,4) | 8194 | 1280
(4 rows)
然后进行vacuum freeze ,居然说已经删除的三个元组居然不能被freeze。
postgres=# vacuum VERBOSE a;
INFO: vacuuming "public.a"
2473685768INFO: "a": found 0 removable, 4 nonremovable row versions in 1 out of 1 pages
DETAIL: 3 dead row versions cannot be removed yet, oldest xmin: 2473685768
There were 0 unused item pointers.
Skipped 0 pages due to buffer pins, 0 frozen pages.
0 pages are entirely empty.
CPU: user: 0.00 s, system: 0.00 s, elapsed: 426.94 s.
VACUUM
通过debug,发现原因是这三个元组的t_xmax的在OldXmin之后的(HEAPTUPLE_RECENTLY_DEAD)。
/*
* Deleter committed, but perhaps it was recent enough that some open
* transactions could still see the tuple.
*/
if (!TransactionIdPrecedes(HeapTupleHeaderGetRawXmax(tuple), OldestXmin))
return HEAPTUPLE_RECENTLY_DEAD;
TransactionIdPrecedes(2473735755,2473685768) = 0。
(gdb) finish
Run till exit from #0 TransactionIdPrecedes (id1=2473735755, id2=2473685768) at transam.c:308
0x0000000000a342d0 in HeapTupleSatisfiesVacuum (htup=0x7ffe5082ccc0, OldestXmin=2473685768, buffer=163) at tqual.c:1377
1377 tqual.c: No such file or directory.
in tqual.c
Value returned is $16 = 0 '\000'
在PgSQL中的txid是unsigned int32类型,但是判断行版本新旧的方式是通过将做差,然后转换为int型的方式比较。
diff = (int32) (id1 - id2);
return (diff < 0);
其实就是判断两个长度为32的补码表示的二进制数的大小,补码中的头尾相接。
符号相同的话好理解,差值如果大于2^31,就会变号;
如果符号不同,可以看成(正数-0 + 2,147,483,648+负数)
比如长度为4的二进制数,用补码表示0010 - 1001=0111。
=> 0010 - 0 + 10000-1001
vacuum_defer_cleanup_age
描述了这么多,问题是2473685768是从哪来的?
* GetOldestXmin -- returns oldest transaction that was running
* when any current transaction was started.
GetOldestXmin() - vacuum_defer_cleanup_age
postgres=# show vacuum_defer_cleanup_age ;
vacuum_defer_cleanup_age
--------------------------
50000
(1 row)
postgres=# select 2473685778+50000;
?column?
------------
2473735778
(1 row)
postgres=# select txid_current();
txid_current
--------------
2473735778
(1 row)
解决方案
迁移用户数据
由于之前出现这种问题,通过删除数据的方式解决,现在没有找到删除数据的方法。决定通过逻辑复制的方式,将业务数据复制出来,而不是直接修复系统表。
由于出现问题的是有两个系统表,在没有迁移业务数据之前,该库上这两个表的Autovacuum都会受到影响。之前每天晚上的vacuum任务是对整个库的vacuum,由于出现上述报错,导致vacuum中止。因此,现在每晚的vacuum变成,将每个表进行分别vacuum。
虽然整体库的年龄在不断增长,但是业务表的年龄并不大,只是运维起来比较麻烦。
对于每次查询得到一个txid,只要没有行版本<(txid_current-2billion),那么就不会出现错误情况(过去的数据,出现在将来了)。
留下的有问题的老库,作为一个研究对象,后期进行研究。
二进制打开硬改xmin
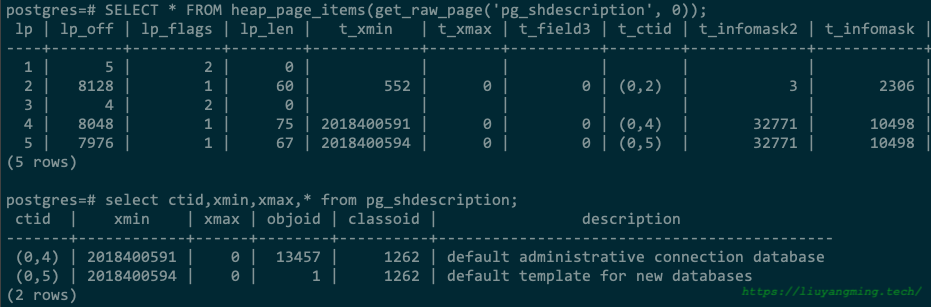
postgres=# select lp , lp_off , t_xmin, t_xmax, t_field3, t_ctid, t_infomask2, t_infomask from heap_page_items(get_raw_page('pg_shdescription',0));
lp | lp_off | t_xmin | t_xmax | t_field3 | t_ctid | t_infomask2 | t_infomask
----+--------+------------+--------+----------+--------+-------------+------------
1 | 5 | | | | | |
2 | 8128 | 552 | 0 | 0 | (0,2) | 3 | 2306
3 | 4 | | | | | |
4 | 8048 | 2018400591 | 0 | 0 | (0,4) | 32771 | 10498
5 | 7976 | 2018400594 | 0 | 0 | (0,5) | 32771 | 10498
(5 rows)
postgres=# select pg_relation_filepath('pg_shdescription');
pg_relation_filepath
----------------------
global/2396
(1 row)
552是有问题的记录。vim -b global/2396打开文件,硬改。将552改成和其他正常记录一样的xmin。
由于文件有缓存,这里利用重启的方式,重新加载文件。
[postgres@ymtest affdata]$ pg_ctl restart -D affdata2
waiting for server to shut down.... done
server stopped
waiting for server to start....,,104960,,,1,,00000,0,,2019-01-18 15:51:00 CST,LOG: listening on IPv4 address "0.0.0.0", port 8888
,,104960,,,2,,00000,0,,2019-01-18 15:51:00 CST,LOG: listening on IPv6 address "::", port 8888
,,104960,,,3,,00000,0,,2019-01-18 15:51:00 CST,LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.8888"
,,104960,,,4,,00000,0,,2019-01-18 15:51:00 CST,LOG: listening on Unix socket "/tmp/.s.PGSQL.8888"
,,104960,,,5,,00000,0,,2019-01-18 15:51:00 CST,LOG: redirecting log output to logging collector process
,,104960,,,6,,00000,0,,2019-01-18 15:51:00 CST,HINT: Future log output will appear in directory "log".
done
server started
[postgres@ymtest affdata]$ psql -p 8888 -h /tmp
psql (10.4)
Type "help" for help.
postgres=# select lp , lp_off , t_xmin, t_xmax, t_field3, t_ctid, t_infomask2, t_infomask from heap_page_items(get_raw_page('pg_shdescription',0));
lp | lp_off | t_xmin | t_xmax | t_field3 | t_ctid | t_infomask2 | t_infomask
----+--------+------------+--------+----------+--------+-------------+------------
1 | 5 | | | | | |
2 | 8128 | 2018400591 | 0 | 0 | (0,2) | 3 | 2306
3 | 4 | | | | | |
4 | 8048 | 2018400591 | 0 | 0 | (0,4) | 32771 | 10498
5 | 7976 | 2018400594 | 0 | 0 | (0,5) | 32771 | 10498
(5 rows)
我们看到552变成了2018400591;接着进行vacuum freeze,成功。
postgres=# vacuum FREEZE VERBOSE pg_shdescription;
INFO: vacuuming "pg_catalog.pg_shdescription"
INFO: index "pg_shdescription_o_c_index" now contains 3 row versions in 2 pages
DETAIL: 0 index row versions were removed.
0 index pages have been deleted, 0 are currently reusable.
CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s.
INFO: "pg_shdescription": found 0 removable, 3 nonremovable row versions in 1 out of 1 pages
DETAIL: 0 dead row versions cannot be removed yet, oldest xmin: 2579204406
There were 0 unused item pointers.
Skipped 0 pages due to buffer pins, 0 frozen pages.
0 pages are entirely empty.
CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s.
INFO: vacuuming "pg_toast.pg_toast_2396"
INFO: index "pg_toast_2396_index" now contains 0 row versions in 1 pages
DETAIL: 0 index row versions were removed.
0 index pages have been deleted, 0 are currently reusable.
CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s.
INFO: "pg_toast_2396": found 0 removable, 0 nonremovable row versions in 0 out of 0 pages
DETAIL: 0 dead row versions cannot be removed yet, oldest xmin: 2579204406
There were 0 unused item pointers.
Skipped 0 pages due to buffer pins, 0 frozen pages.
0 pages are entirely empty.
CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s.
VACUUM
关于重新加载文件
这里采用重启的方式,重新加载表文件;能否不重启呢?PG执行了checkpoint;以及OS执行了sync; echo 3 > /proc/sys/vm/drop_caches都不行。怀疑是PostgreSQL将系统表的信息单独放在自己的sharedbuffer中,由于PostgreSQL并不觉得这个表的数据页脏了,所以checkpoint的时候也不会更新,并且checkpoint的更新也只是更新磁盘文件,只能覆盖我们的修改而不是读取;
另外,综合整个PostgreSQL的生命周期,只有两种情况会读取磁盘文件。
启动后,当我们读取系统表的时候才会去shardbuffer中读取(没有命中,会从磁盘加载)。
已经读取的页,由于换出策略换出了,重新加载,而这种情况,我们只能改好磁盘文件,干等这个发生了。
/*
* get_raw_page
*
* Returns a copy of a page from shared buffers as a bytea
*/
PG_FUNCTION_INFO_V1(get_raw_page);
进一步思考
我们都知道PostgreSQL的txid是uint32的整型标识,最大值就大约为20亿;如果到达最大值会怎么样?
到达最大值MVCC的版本就会乱套了,为了避免这个事情发生,当txid与最大值只相差不到100万的时候,PostgreSQL就会拒绝服务。这时候作为DBA改怎么办?
- 停止DB
- 单用户模式重启
- 执行vacuum
上述是极端情况,在PostgreSQL中本身有个autovacuum进程来进行MVCC的版本维护操作,其有两种模式:lazy和eager,通过如下的查询我们可以监控系统版本资源的水位:
WITH max_age AS (
SELECT 2000000000 as max_old_xid
, setting AS autovacuum_freeze_max_age
FROM pg_catalog.pg_settings
WHERE name = 'autovacuum_freeze_max_age' )
, per_database_stats AS (
SELECT datname
, m.max_old_xid::int
, m.autovacuum_freeze_max_age::int
, age(d.datfrozenxid) AS oldest_current_xid
FROM pg_catalog.pg_database d
JOIN max_age m ON (true)
WHERE d.datallowconn )
SELECT max(oldest_current_xid) AS oldest_current_xid
, max(ROUND(100*(oldest_current_xid/max_old_xid::float))) AS percent_towards_wraparound
, max(ROUND(100*(oldest_current_xid/autovacuum_freeze_max_age::float))) AS percent_towards_emergency_autovac
FROM per_database_stats