总体结构
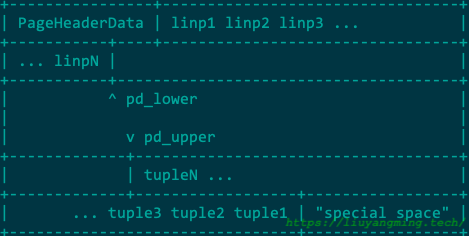
PostgreSQL的堆表由多个页组成。业内结构如上图所示(代码readme中),由5部分构成,如下。
| 模块 | 描述 |
|---|---|
| 页头 | 24字节长,包含页内的总体信息与空闲空间的位置。 |
| 行指针 | 每个行指针占4个字节,由两项信息构成(offset,length) ,指向实际的Tuple数据。 |
| 空闲空间 | 页内未分配的空间,如果FreeSpace剩下的空间放不下一个元组,那么该页就是满了。新的行指针从空闲空间的头部开始分配,相应的Tuple数据从空闲空间的尾部开始分配。 |
| Tuple | 实际的Tuple数据 |
| 特殊空间 | 如果是索引页,那么根据索引类型的不同存储的数据也不同。 |
Page Header
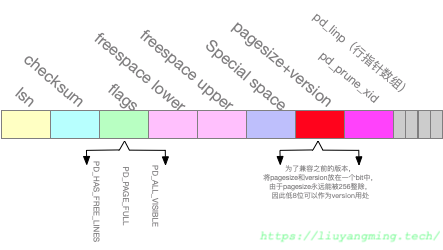
- LSN:在BufferManager中,为了保证WAL的原则(thou shalt write xlog before data),对每个块标记了一个日志序列号(Log Sequence Number)。
- prune xid:PostgreSQL中有一个对页内空间进行整理的过程,该列记录了上一个对页进行整理的xid。
Item ID(行指针)
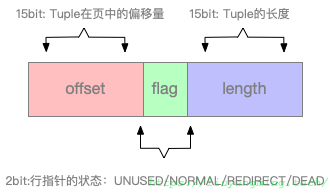
包括偏移和长度两个信心,另外还有一个标记位,标记该行指针的状态。为了节省空间,代码中多处Struct中标记了位域,如下,行指针只占4个字节了。
typedef struct ItemIdData
{
unsigned lp_off:15, /* offset to tuple (from start of page) */
lp_flags:2, /* state of item pointer, see below */
lp_len:15; /* byte length of tuple */
} ItemIdData;
Tuple
Tuple Header
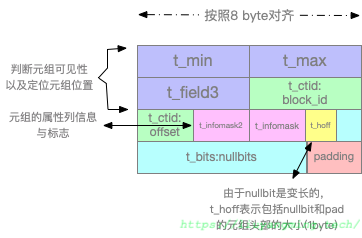
Tuple头部是由23byte固定大小的前缀和可选的NullBitMap构成。
postgres=# SELECT pg_column_size(row());
pg_column_size
----------------
24
如上,一个空行的大小是24byte,说明最后一个byte被对齐了;
postgres=# SELECT pg_column_size(row(NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL));
pg_column_size
----------------
24
而一个有8个空值的行的长度也是24byte,说明最后一个byte当做了bitmap;
postgres=# SELECT pg_column_size(row(NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL,NULL));
pg_column_size
----------------
32
有超过8个空值后,那么就需要重新按照8字节对齐。在Tuple数据中,不会存储Null数据。
另外在t_infomask2和t_infomask中,存储了属性列的个数以及若干标记位,其中就包括HEAP_HASNULL(标识bitmap存不存在),如下。
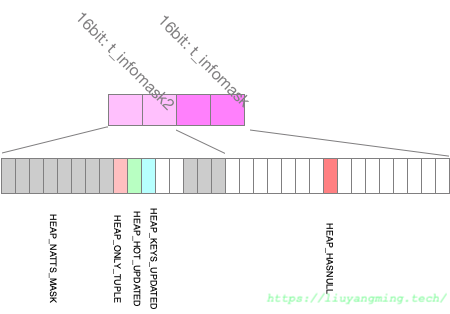
Tuple data
Tuple由多种类型构成。在PostgreSQL中,pg_type系统表中记录了各种类型的信息;通过如下查询,我们可以知道每个类型的传递方式(值or引用),长度以及对齐方式(和C结构体对齐相似)。
postgres=# select typname,typbyval,typlen,typalign from pg_type limit 3;
typname | typbyval | typlen | typalign
---------+----------+--------+----------
bool | t | 1 | c
bytea | f | -1 | i
char | t | 1 | c
(3 rows)
长度列存在负数,负数是对应于变长类型。其中,-2对应的是cstring和unknown类型。-1对应的是其他变长类型。
类型对齐方式有几种取值,分别对应不同长度的对齐:c(char,1),s(short,2),i(int,4),d(double,8)
对齐存储
当你创建一个数据表时,通过检查
pg_type中属性长度,合理安排属性顺序,可节省空间,如下例所示。postgres=# CREATE TABLE t1 (a char , b int2 , c char , d int4 , e char , f int8); CREATE TABLE postgres=# CREATE TABLE t2 (f int8 , d int4 , b int2 , a char , c char , e char); CREATE TABLE postgres=# insert into t1 values ( 'a',1,'a',1,'a',1); INSERT 0 1 postgres=# insert into t2 values ( 1,1,1,'a','a','a'); INSERT 0 1 postgres=# create extension pageinspect ; CREATE EXTENSION postgres=# select lp, t_data from heap_page_items(get_raw_page('t1', 0)); lp | t_data ----+---------------------------------------------------- 1 | \x056101000561000001000000056100000100000000000000 (1 row) postgres=# select lp, t_data from heap_page_items(get_raw_page('t2', 0)); lp | t_data ----+-------------------------------------------- 1 | \x0100000000000000010000000100056105610561 (1 row)
变长属性列
每个PostgreSQL类型都有一个存储方式,如下查看test表的结构,其中表示了每个列的存储方式。
postgres=# \d+ test
Table "public.test"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+-------------------+-----------+----------+---------+----------+--------------+-------------
a | boolean | | | | plain | |
b | character varying | | | | extended | |
可以看出来boolean类型的存储方式是plain,varchar的存储类型是extended。存储方式共有4种:
- PLAIN :避免压缩和行外存储。
- EXTENDED :先压缩,后行外存储。
- EXTERNAL :允许行外存储,但不许压缩。
- MAIN :允许压缩,尽量不使用行外存储更贴切。
那么,何时压缩数据?何时行外存储呢?
Tuple压缩:当Tuple大小超过大概2KB时,PostgreSQL会尝试基于LZ压缩算法进行压缩。
行外存储(TOAST):toasted属性的本意是The Oversized-Attribute Storage Technique,对于某个超长的属性单独存储。当某行数据超过PostgreSQL页大小(8k)后,会将这个页放到系统命名空间pg_toast下的一个单独的表中,而在原表中存储一个TOAST pointer,如下。
typedef struct
{
uint8 va_header; /* Always 0x80 or 0x01 */
uint8 va_tag; /* Type of datum */
char va_data[FLEXIBLE_ARRAY_MEMBER]; /* Type-specific data */
} varattrib_1b_e;
typedef struct varatt_external
{
int32 va_rawsize; /* Original data size (includes header) */
int32 va_extsize; /* External saved size (doesn't) */
Oid va_valueid; /* Unique ID of value within TOAST table */
Oid va_toastrelid; /* RelID of TOAST table containing it */
} varatt_external;

启发
了解了PostgreSQL的Tuple细节,对我们使用PostgreSQL有什么启发呢?
- 如果没有NULL值且没有变长字段,那么Tuple的长度是可以估计的;
- 合理排列Tuple列,可以减少表占用空间。
- 首先是Not NULL固定长度的属性。
- 其次是合理排列固定长度的属性
- 将所有变长列放到右边