- Data Event Order
- Data Race Safety On Specific Node
- Multi-Node Data Consistency
- Multi-Data Race Safety On Multi-Node
A system is distributed if the message transmission delay is not negligible compared to the time between events in a single process. —— Leslie Lamport
为了解决了单机的瓶颈,包括容量、吞吐等各个维度,有了分布式系统;相比于单机,分布式引入了网络这一更加不可控的因素,使得完成同样一件事,需要更加复杂的协议保证。本文是笔者对分布式系统概貌的初步了解,通过此文让不从事分布式系统相关工作的人能够回答一个基本问题——分布式系统中,用了什么技术,解决了哪些在单机环境中不需要解决的问题?
Data Event Order
首先就是如何确定多机上进程的先后关系,特别是当进程间存在依赖的时候。
在单机中,可直接用本地时间标识事件的先后;而分布式环境中,可以将时间戳做成一个服务,其他节点来这个节点进行请求。
另外,还可以通过消息传递进行时钟同步,产生一个全局的逻辑时间戳。在《Time, Clocks, and the Ordering of Events in a Distributed System》论文中,详细阐述了通过节点间的消息传递,实现逻辑时钟的实现协议;实现的方式是通过定义了节点间时间同步的一个协议,生成逻辑时间,获得了事件的一个全序关系。这分布式逻辑时间,在很多分布式数据库中作为数据版本号来使用,比如CockroachDB。
另外,还可以使用满足一定条件的物理时钟,目前采用这种方式的只是Google Spanner。
Data Race Safety On Specific Node
第二个问题就是分布式环境中,各个服务之间的操作同步;单机中可以通过mutex或semaphore进行同步,分布式系统中的进程同样需要相同的机制来处理Data Race问题。但是在分布式系统中Network Delay和Clock Error的存在,使不同Node的进程同步变得复杂;一般的解决方案是专门设计一个Lock Service;通过Lock Service进行锁的管理;经典的就是基于Redis实现Distributed Lock——RedLock,其加锁流程如下:
- client get local time(T1);
- client communicate with N redis nodes;
- client get local time again(T2);
- check whether T2-T1 ≥ TTL;
- access locked resource.
RedLock通过TTL确保Owner Crash后不会死锁,并且假设本地时钟误差(Clock Error)远小于TTL,这样确保加锁的安全性,即同一时间只有一个Owner获得锁;但是墨菲定律告诉我们, 如果会发生的坏事,那么一定会发生,不管几率多小;因此,对安全性要求高的场景中,RedLock需要强化。
因为RedLock通过Step1和Step3的时间差规避了Network Delay的影响,但是如果在Step4检查成功后,Client段进程暂停了(带有GC的语言程序或者CPU调度等情况),或者Redis Server段的本地时间发生跳跃,那么当Client重新执行Step5的时候,其获得的锁其实已经释放了;如果这时另一个Client又取得了锁,那么系统就发生的Data Race。
通常采用Fence Token的方式,就是当我们从Lock Service取锁的时候,同时取的一个全局单调递增的Token;当后续访问Resource Service的时候,Resource Service判断当前请求是否大于自己最新的Token,拒绝过期Token的请求;可以看出来,这种方式需要Resource Service的配合,这实际上在分布式系统中就建立了一种简单的协议,分布式系统中要完成一项工作,往往就多节点都遵循某一协议才行;本文也是考虑的是在这种可信的网络中通信,如果在存在拜占庭的情况,即某些Node会故意欺骗,那么就分布式系统更难解决了。
回到这一问题中,这里我们讨论的都是基于Redis的RedLock,其实很多人认识zookeeper、etcd等具备Strong Consistency的服务更适合作为Lock Service。这些服务的核心就是Consensus算法,通过Consensus达成Consistency。
Multi-Node Data Consistency
上节中,如果通过Redis是想Lock Service,则Lock Service的HA是个问题;如果采用主从复制的话,需要解决主从延迟的问题;而Consensus算法的出现就是解决多副本之间的一致性,常用的有raft,paxos;和Consensus很相关的有个著名理论——CAP。
CAP theorem
对于多副本的分布式集群,CAP告诉我们需要主要C/A/P之间进行Tradeoff,没有同时满足三者的系统,CAP分别表示:
Strong Consistency
:Client访问任何一个node,都是看到
相同的且最新的
数据,并且能够成功的写入;满足C,则要求是达到Strong Consistency,但是如果该维度可以Tradeoff,那么可以选择低级别的一致性,比如:
- – Weak: 所有副本最终会达到一致,但是当前不一定一致。
- – Quorum: 对于提交的数据, 大多数的副本是有相同的值。
Perfect A**vailability:每个有效节点都能在合理的时间**内响应读写请求;关键在于保障节点的持续服务能力,在性能更加关键的场景,通常放弃Consistency选择HA。
Partition Tolerant:由于网络隔离或机器故障,将系统分割后,系统能够继续保持服务并且保持一致性;当分割恢复后,能够优雅的恢复回来。
这里的CA和ACID中的CA是两码事。A就不用说了,一个是可用性,一个是原子性。
ACID中的C是Consistency,强调的是连贯性,前后一致。
CAP中的C是Consensus,强調的是共识,各个节点之间是否达成一致意见。
由于CAP三者不能同时满足,从而有状态的分布式系统就分为了三种类型:
- CP:当系统出现网络分区时,这时牺牲了可用性,保障整体一致性和分区容忍性。
- AP:当系统出现网络分区时,这时牺牲了一致性,保证性能可用性和分区容忍性。
- CA:如果单机的DB算一个分布式系统,那么就算一个CA的系统。但是,网络分布式系统中,由于node之间是通过网络进行通信的,网络分割是常有的事。分布式系统中一定要处理P这个问题,因此很少有分布式的CA系统。
综上来说,分布式系统一般就是在考虑在产生网络分区时,我们应该优先保证强一致性还是完美的可用性。尽管不能两全,但是我们尽量两方面都做到尽量好。对于AP系统,比如一些NoSQL的分布式存储系统,这种系统的主从Node可以采用异步同步,减少Node的不可用时间;对于CP系统,不同Node间通过Consensus算法达成Consistency。
这里说的Consistency都是讨论某组数据分片的多个副本中数据是否一致,而从全局来看,用户更需要的是整体数据的一致性,这就需要分布式事务的保证,见下节。
Multi-Data Race Safety On Multi-Node
事务是DB中并发控制的基本单位,需要满足用户要求的ACID;C/D两个维度好解决,更多讨论集中在A/I这两个维度,即Atomic Commit和Concurrency Control。
Atomic Commit
那么,对于单机事务,更容易在全局维护事务Commit状态,并且同时可以很好进行并发控制。而对于分布式事务,其实原理是类似的,通常也有个全局事务管理器,作为Coordinator,通过2PC提交事务,并记录事务Commit状态;而对于并发控制则更多的采用MVCC;毕竟分布式的网络开销已经很大了,如果还采用2PL,开销有点大。
2PC有时也叫XA,是X/Open提出的通用的分布式事务处理协议,在PostgreSQL和MySQL的多机事务都是采用这种方式(在MySQL内部的SQL层与存储层同样也是采用2PC的方式进行事务提交)。
在2PC中一般有两个角色,一个全局协调者的TM(Transaction Manager)与多个本地存储服务的RM(Resource Manager)。2PC的两个阶段如下:
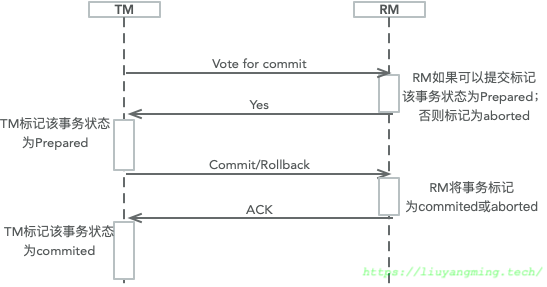
理想情况是:在voting阶段,如果RM节点返回了Yes;那么提交成功。否则,全部回滚。如果某个RM节点在返回Yes之前挂了,那么TM可以感知到从而进行Rollback。如果在返回Yes之后挂了,那么此时这个全局事务同样标记为Commit;当挂掉的RM节点重启恢复的时候,本地发现还有未提交的Prepared的全局事务,此时会重新查询TM中全局事务的状态,来决定对其进行Commit还是Rollback。
2PC基本模型有一些明显的弊端,比如阻塞等待,容错性等;目前的系统中,基本都是基于2PC的优化版本,举几个🌰:
- 2PC的RM在返回Yes之后,处于阻塞的状态;如果此时TM挂了,那么系统就阻塞住了?
- RM进行设置了Timeout。
- 2PC在commit阶段,RM先标记事务在本地commit,此时TM和RM都挂了;那么,系统recover后,TM中事务是Prepared,而某个RM中却是Committed,这造成了数据状态的不一致?
- 可将commit阶段,分为precommit/docommit;这样在precommit阶段,如果都返回成功了,那么TM中先将该事务可标记为提交了;然后,通知各个节点真正做提交这个动作,即使此时TM和RM节点都挂了,那么recovery时RM可以通过TM中的状态,确定RM中事务是否应该提交,不会造成数据不一致的情况。
- 2PC的两次通信的阻塞等待延迟过高?
- 基于共识算法进行关于commit/aborted的决策,这样RM就作为consensus cluster的client进行请求即可,但是前提是RM都已经处于Prepared的状态了。
Concurrency Control
在单机环境中,一般有三种方式进行并发控制:
- MVCC:多版本并发控制。数据带上和事务标识相关的版本号。
- S2PL:严格两阶段提交协议;比起2PL,S2PL直到事务结束才释放写锁。
- OCC:乐观并发控制。在冲突较低的场景下,在事务结束才判断是否冲突,提高性能。整个事务就分为三个阶段:执行、确认、提交。在确认阶段有一些判断规则。
相应地,在分布式环境中有基于同样思想的并发控制:
- Distributed 2PL:系统中有一个或若干个锁管理器节点,该节点负责全局的锁分配和冲突检测。
- Distributed MVCC:这里需要有一个全局唯一的自增ID(或时间戳),参考第一节提到的Order服务。
- Distributed OCC:和单机环境相同。但是在确认阶段有一些分布式环境中相应规则。
分布式锁在前文已经介绍了,可以看出锁在分布式场景中的代价比较高,通常只用于单一资源的同步访问;对于事务来说,通常需要取得多个资源的,为了提高DB整体的效率,通常是基于MVCC/OCC的方式进行并发控制。不过是哪种方法,都是为了进行多个全局事务的读写同步,从而保证Isolation。说起Isolation,不得不提Isolation Level;
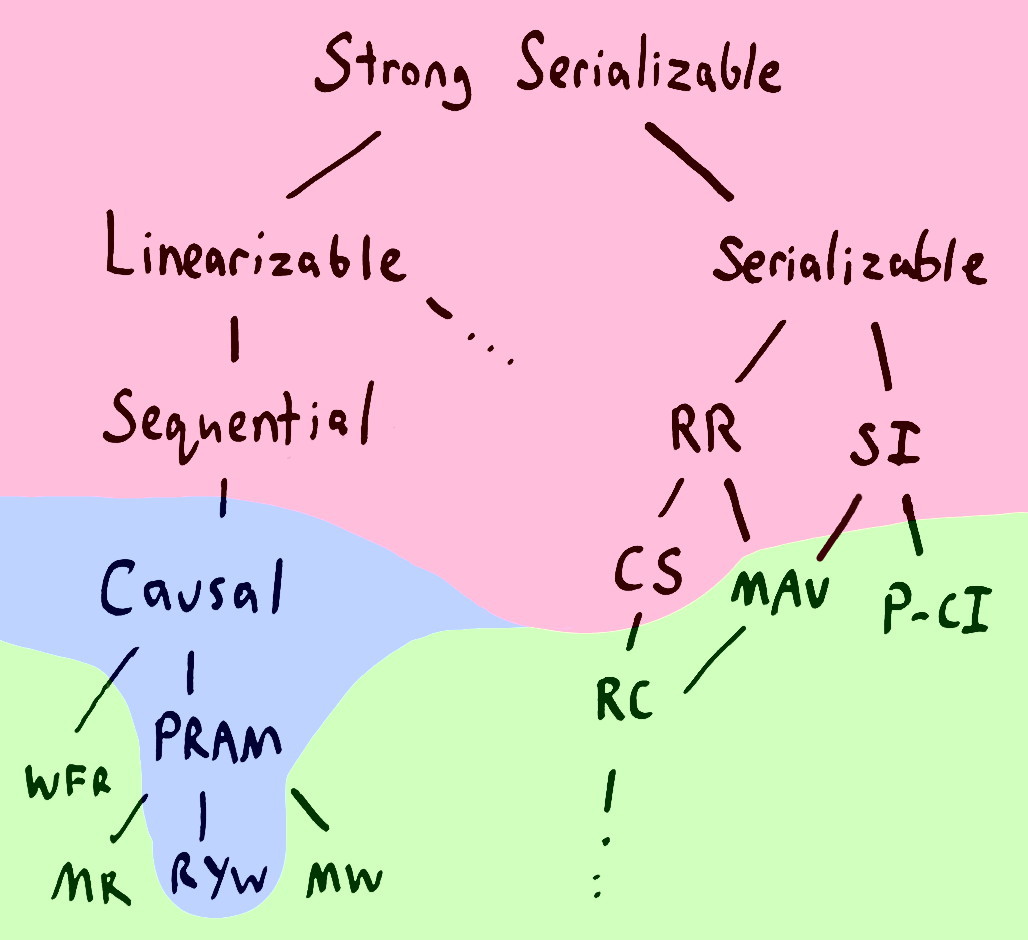
不同的Level中,不同的Client会读到不同的数据库的数据,换句话说,就是达成了什么样Consistency?区别于上节,Consensus中提到的Consistency是Data-centic Consistency,这里是Client-centic Consistency;我们常说的“我们的数据库产品,可以提供全局读一致性”就是站在Client的角度考虑的。