BlockBasedTable是RocksDB中最常用的SST格式,在wiki中,对其格式有个大概的介绍,但是对其中对一些细节之处并没有特别清晰的介绍,本文作为该wiki的补充,特别对Index部分进行详细阐述。
- 读写
表如其名,BlockBasedTable的Block是按照Block为单位进行组织,但是注意其block_size在磁盘中不是固定大小的,只是一个CompressUnit;当BuildTable的时候,通过FlushBlockBySizePolicy判断是否该Flush当前的Block;与BlockBasedTable强相关的是BlockCache,在读的时候缓存Block;在RawBlock的最尾部的字节标记了其压缩算法,我们说的BlockCache一般是指存储UncompressedBlock,而还可以配置一个CompressedBlockCache,不过这个Cache在插入的时候不返回CacheHandle,即,当场Release;可见其只是作为BlockCache的页缓存,有点像PageCache;而BlockCache是TableReader的直接Cache。
- Block
说回BlockBasedTable的Block,和InnoDB相似,Block内部也有一个稀疏的二分索引(restartOffsets);因为Block内的key是有序的,其可用很容易的利用prefix compress进行压缩,这样对于一段key,只保留第一个完整key,段内后续key只需保留一个delta即可;那么restartOffsets数组中就是保存了每个段头的offset。另外其实还有个可选的Block内部的DataBlockHashIndex,如果data_block_index_type为kDataBlockBinaryAndHash, BlockBuilder中就会构建hashindex,这些Block内索引信息都存储在BlockFooter中,一起压缩存储。
值得注意的是,在落盘后还会追加一个固定大小(5 bytes)的BlockTailer,其中再存储了1byte的compresstype和4byte的checksum。在BlockFetcher读取的时候,将CompressedBlock和Tailer一起读上来,那么compress_type正好就是rawblock_data[block_size]。
- Index
BlockBasedTable的检索方式就是二分,默认的index_type为kBinarySearch;每个Block的last_internalkey和该Block的BlockHandle,作为IndexBlock的entry;TableReader在Open后,将IndexBlock留在内存,Get的时候在其中进行BinarySearch定位到Key所在的Block;由于BinarySearch的CPU代价比较高(将近30%),RocksDB提出了一个可选的HashIndex,更应该叫PrefixHashIndex,当index_type=kHashSearch且Options.prefix_extractor存在的时候,将构建额外的HashIndex,通过Key的Prefix直接定位Block(记住这是有额外内存代价的,并且和prefix的数量相关)。
HashIndex的两个优化:
- 为了TableReader构建HashIndex时频繁的malloc,这里将Prefix的内容 和 具体的元信息分开存储。在BlockPrefixIndex::Create中,最终Reader构建Index的时候,在prefixes所在内存上套个slice,避免了copy和malloc;meta则是需要一个个copy到新的variable中。
- 当Prefix多的时候,之前基于std::unordered_map存储的内存代价很大,考虑到HashIndex只起到定位的作用,其实可以不用存PrefixKey;因此HashIndex只需构建了一个blockHandle的array,BlockPrefixIndex::GetBlocks只需计算好的Hash值,即可array的slot;当然这有个弊端,当Key不存在的时候,需要读取block来判断。
HashIndex的引入是为了解决Binary Search CPU高的问题,先通过标准的unordered_map快速实现拿到预期的收益后,再继续针对Prefix多的用户场景做优化,算是一个避免过早优化例子。
综上,BlockBasedTable的内部布局如下图所示:
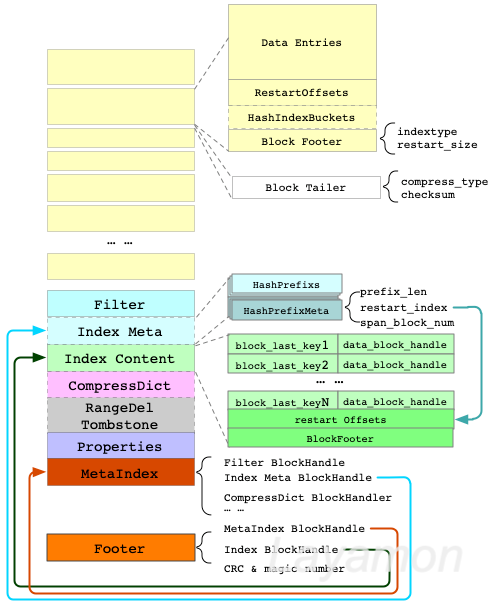
值得注意的是,IndexBlock也是按照DataBlock的方式进行组织,HashIndex存储在IndexBlock之可选的IndexMeta区域(HashPrefix的数据和meta是分开存储的,这是个上面讲的一个小优化),构建的HashIndex返回的还是IndexBlock中的RestartIndex(即RestartOffsets的下标)。
BuildIndex的时候,IndexBlock逐条添加Key,与此同时维护Block内部的RestartOffsets;当启用HashIndex后,那么IndexBlock会同时维护各个HashPrefix对应的prefix和RestartIndex,最后将这些数据写到IndexBlock的indexmeta区域(其实就是IndexBlock中的一个特定的Key,后续通过BlockIter.Seek定位并加载)。
另外,还有一些辅助的信息,比如filter、TombStone等;对于CompressDict信息,我之前一直理解有偏差;这个不是必选的,默认关闭,通过设置max_dict_bytes打开,能够提高压缩率,但同时提高了整体的内存使用率。
那么以上就是对BlockBasedTable在wiki之外的延伸,对于想了解BlockBasedTable具体实现细节的同学希望能有帮助。