Log Manager
Btree系列的存储引擎的数据都是UpdateinPlace的,那么整个库的变更只有一个入口,就是用户的增删改;而RocksDB是AppendOnly的,磁盘数据组织成若干个 Static Sorted Table;虽然Sst中的数据不会改变,但是会有后台任务对Sst构成的LSM-tree进行修正,确保一个良好的形态;因此,RocksDB的Log Manager需要对两类信息进行记录:
- ***.LOG:kv pair的Write Ahead Log。
- MANIFEST:sstfile的快照——VERSION的变更,记录的是Background JOB对sst的变更。
说Btree类的存储引擎的数据只有一个变更入口也不太准确,PostgreSQL后台的Vacuum、MySQL后台的Purge等任务同样需要整理Page中的数据;不过这类存储引擎通常使用的事Physilogical的Redolog,虽然page会被修整,但是某条Key对应的Btree中的逻辑位置在写入的那一刻就确定了,比如PostgreSQL的ctid。
WAL
RocksDB的写入是组织成一个个的WriteBatch,WAL的构成也很简单,就是直接当WriteBatch放进去;不过在物理上也会划分成若干个kBlockSize,那么一个Batch在写入到WAL中,可能会切分为多个LogRecord;Block可能会包含多个LogRecord,LogRecord不能跨多个Block,但是WriteBatch可能会跨多个Block,不过不会跨LOG存储。
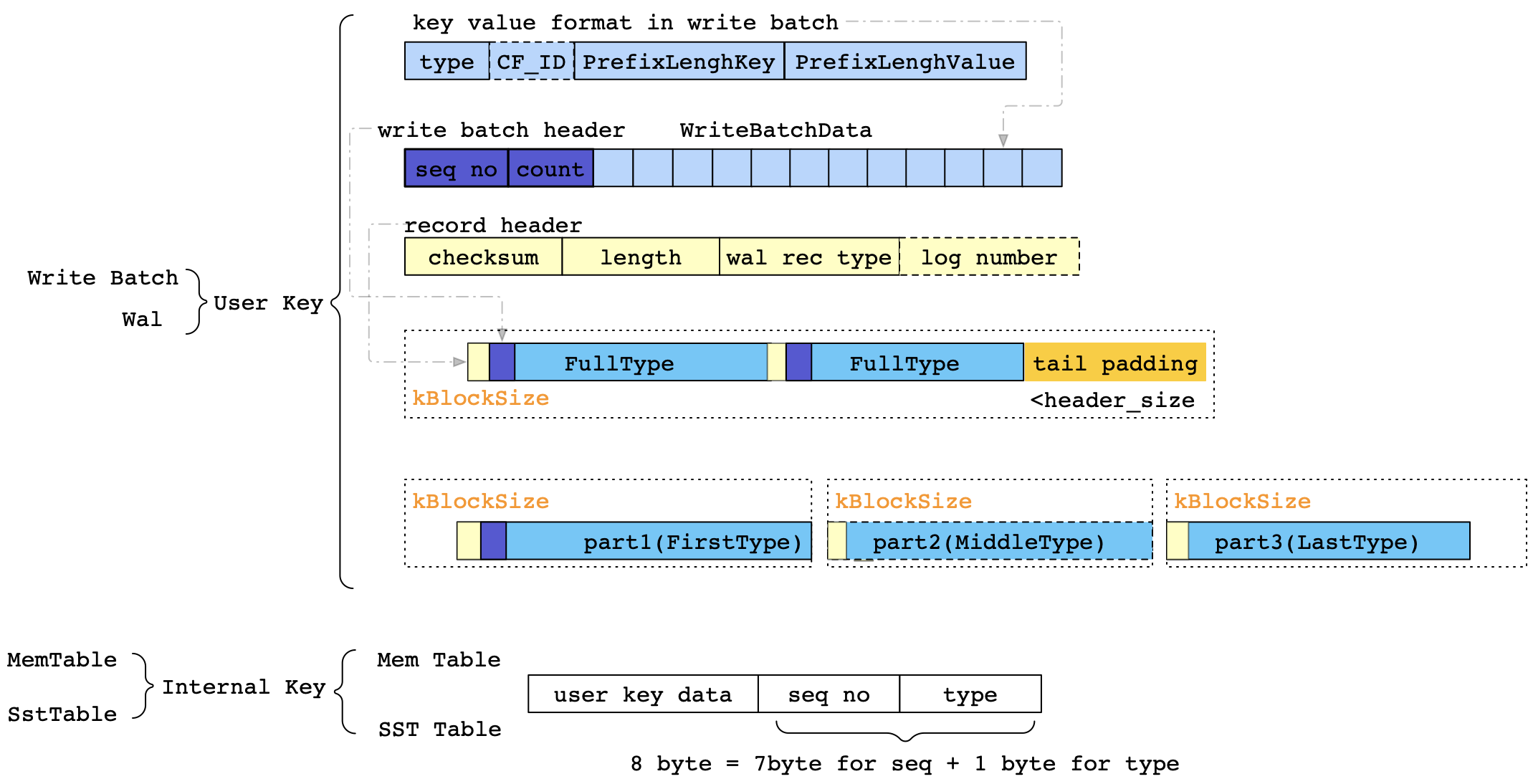
再回顾一下,为什么会需要WAL呢?在传统的Btree的存储引擎中,一般会有一个BufferManager;对于Buffer中的数据的持久性就是通过WAL保证的。而在RocksDB中,刚接触的时候会将BlockCache与PG/MySQL中的BufferPool对应上,但是其实不是;而在这里应该是MemTable,即RocksDB中的WriteBufferManager;BlockCache是ReadCache。
想想Btree中如何通过Checkpoint等机制来联动WAL与BufferPool,RocksDB同样是将WAL与MemTable联动的;即,每当内存数据(memtable)刷新到磁盘之后,都会新建一个WAL,见SwitchMemtable。
MANIFEST
MANIFEST同样是需要有序的更新的,和WAL不同的是,更新MANIFEST的对象的BackgroundJob;这里涉及的主要结构如下图:
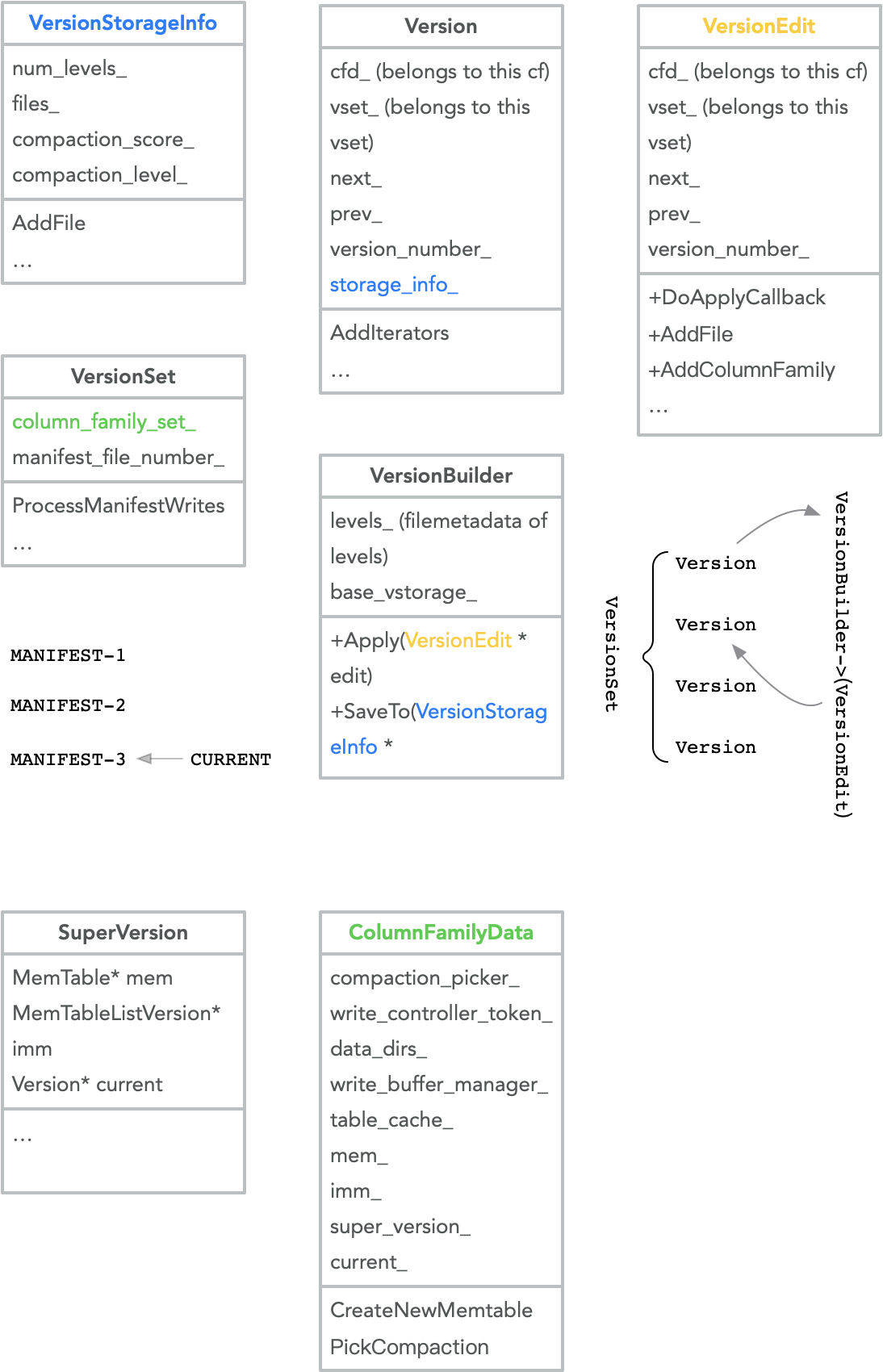
而MANIFEST日志的记录就是这些JOB对LSM-tree的变更——VersionEdit;通过LogAndApply排队写入到MANIFEST中。
一个CF一个Tree,Job一般是以CF为单位的;但是对于AtomicFlush这个特例来说,生成对多个CF的VersionEdit;不过,其实也是分别对多个CF发起FlushJob,然后最后收集到一起再Install。
Group Commit
WAL和MANIFEST都是RocksDB的log;虽然记得是不同维度的东西,但是在存储引擎中,日志是必须串行写入的;
相似地, 为了提高吞吐,RocksDB的WAL/MANIFEST也有类似Group Commit的机制;在WAL中,就是将不同的前台请求的WriteBatch进行合并写;在MANIFEST中,则是将多个后台任务的VersionEdit进行合并写。这样提高了整体的写吞吐。
Question1:在
WriteToWAL中,WAL按理说是顺序写的,每次只需要刷最后一个log就行了,为啥这里要foreach呢?会存在一个GroupWrite对应多个Log的情况吗?存在。在并发写过过程中,在写之前,通过PreprocessWrite处理各种需要切WAL,切MemTable的情况后,取最新的一个log进行写入,那么在实际GroupCommit的时候,会存在多个log。
前台请求通过WriteImpl写入,通过WriteThread结构实现的GroupCommit;由于前台的写会先写WAL,后写MemTable,两个阶段分别做的GroupCommit;
前台请求GroupCommit具体方式就是:在DB全局维护一个write_thread_变量,其中管理了各个GroupCommit点:newest_writer_和newest_memtable_writer_(每个GroupCommit点其实就是一个lock-free的double-linkedlist);在WriteImpl中,创建局部变量WriteThread::Writer,不断将自己挂在对应的GroupCommit点上(LinkOne),如果发现自己是Leader就负责当前list上的Writer的工作;值得注意的是,Leader收集当前Writer的同时,后续的Writer还会接着加到list上,在当前Leader退出的时候,即ExitAsBatchGroupLeader,找到list中的下一个Leader并设置其状态。
后台任务GroupCommit的具体方式是:由于这些Job修改的都是全局元信息,会获取db_mutex,进行互斥(比如,FlushJob在一开始的时候就需要加锁,CompactionJob则是在Install的时候加锁);等到LogAndApply的时候,首先将自己挂在全局的 manifest_writers_队列中,只有当自己是front(即Leader)的时候才会继续执行;在执行PreocessManifestWrites的时候,会收集当前队列中的VersionEdit,组成batch_edits;由于这期间都是加锁的,manifest_writers_的变更是安全的,只有在真正写文件的时候才会放锁。放锁后,这时后续的Job就可以继续追加到队列中,等待下次收割。
总结一下,RocksDB作为一个经典的LSM-tree结构的事务型存储引擎,比起传统的Btree,在LogManager的组成上有一些不同;但是原理上类似,并且优化思路也是和相似的。