简介
CitusDB通过分片(shard)和复制(replication)在物理数据库集群和虚拟机上扩展Postgresql。 其查询引擎将得到的SQL查询,并行化分布到这些机器上,从而支持实时查询
CitusDB并不是Postgresql的一个分支,而是Postgresql的一个扩展,其开发的方式是利用Postgresql的hook和extension API。
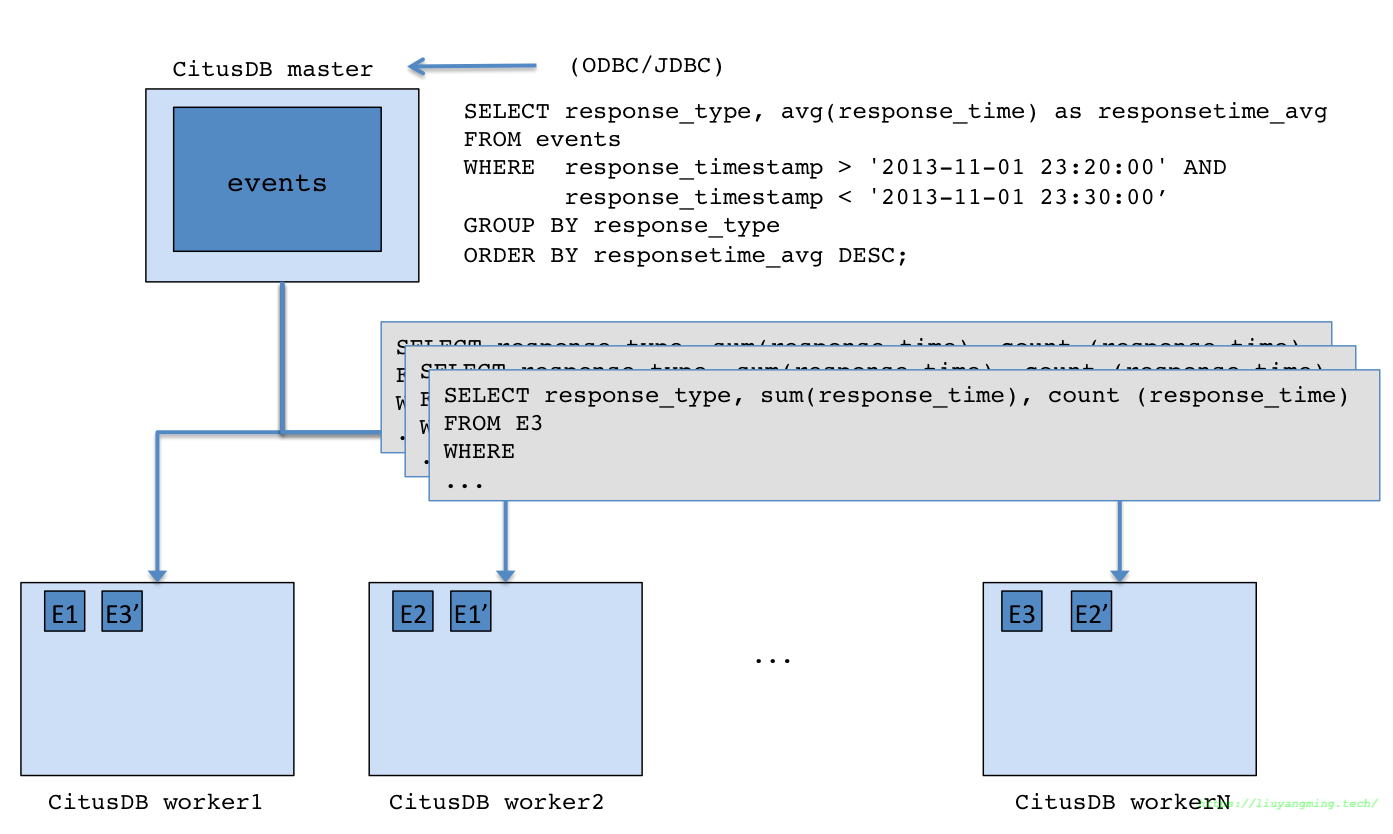
架构图
逻辑分区
类似于HDFS分布式存储的BLOCK,CitusDB使用Postgresql的Table代替file,这些存储在Postgresql中的若干表都是水平分割或者是逻辑分片。于是在Master节点上,就维护了元数据表,来记录所有的节点和节点上的shards。
每个shard在两个或若干节点上备份。并且CitusDB可以随时添加节点,来水平扩展存储和计算的能力。
元数据表
Master中维护这元数据表,其中记录着:
所有的cluster nodes
shard在这些node上的分布
一些统计信息,
比如这些shard的size,min/max,这些统计信息可以用来优化查询计划。 这些元数据表很小(基本就是MB级别)。可以做备份,来应对主节点宕机。 如下一些元数据表示例:
SELECT * from pg_dist_partition;
logicalrelid | partmethod | partkey
--------------+------------+-------------------------------------------------------------------------------------------------------------------------
488843 | r | {VAR :varno 1 :varattno 4 :vartype 20 :vartypmod -1 :varcollid 0 :varlevelsup 0 :varnoold 1 :varoattno 4 :location 232}
(1 row)
SELECT * from pg_dist_shard;
logicalrelid | shardid | shardstorage | shardalias | shardminvalue | shardmaxvalue
--------------+---------+--------------+------------+---------------+---------------
488843 | 102065 | t | | 27 | 14995004
488843 | 102066 | t | | 15001035 | 25269705
488843 | 102067 | t | | 25273785 | 28570113
488843 | 102068 | t | | 28570150 | 28678869
(4 rows)
SELECT * from pg_dist_shard_placement;
shardid | shardstate | shardlength | nodename | nodeport
---------+------------+-------------+-----------+----------
102065 | 1 | 7307264 | localhost | 9701
102065 | 1 | 7307264 | localhost | 9700
102066 | 1 | 5890048 | localhost | 9700
102066 | 1 | 5890048 | localhost | 9701
102067 | 1 | 5242880 | localhost | 9701
102067 | 1 | 5242880 | localhost | 9700
102068 | 1 | 3923968 | localhost | 9700
102068 | 1 | 3923968 | localhost | 9701
(8 rows)
错误处理
类似于HDFS存储策略,若其中有一个节点宕机了,但是别的节点上存在这个数据,那么就可以将,查询这些数据的请求发到其他有这些数据的节点上。 如果这个节点是永久宕机,那么rebalance这些数据即可。
分布式DDL和DML
CitusDB是基于PostgreSQL的hook和扩展API开提供分布式功能的。这就允许用户从PostgreSQL丰富的生态圈中受益。比如,
- 丰富的数据类型(半结构化数据,Jsonb(json-binary)和Hstore)、操作符和函数、全文索引、PostGIS …
- 另外,合理的使用扩展API同样可以使用标准的PostgreSQL的工具,pg_Admin,pg_backup,pg_upgrade;
设计基于以上架构的分布式数据库,需要考虑两个问题,Distribution Column和Distribution Method
Distribution Column
CitusDB中的Distributed Column都有一个列作为Distributed Column,Master维护这个列在每个节点统计信息。 分布式查询计划优化器可以基于这个信息来优化查询。一般选经常作为连接条件,或者过滤条件的列。 这样可以减少网络传输的代价,让一些操作下推到单个节点上执行。比如,比较常用的列就是:
- 时间列
- ID列
Distributed Method
选好数据列后,就是选择Distributed Method:append或者hash。CitusDB同样也支持 range Distribution,但是需要手动设置。
- Append Distribution
从名字上来理解,append Distribution适合于append-only的例子,比如,按时间顺序加载的数据,像网站日志这种的。 append Distribution支持高效的范围查询。
CREATE TABLE github_events
(
event_id bigint,
event_type text,
event_public boolean,
repo_id bigint,
payload jsonb,
repo jsonb,
actor jsonb,
org jsonb,
created_at timestamp
)
-- DISTRIBUTE BY APPEND (created_at);这种方法是在4.0里,现在已经过时了
SELECT master_create_distributed_table('github_events', 'created_at', 'append');
- Hash Distribution
比如userid这种并没有顺序的列,用户能够实时的分析,插入的case。这样CitusDB维护了每个hash range shard的min/max。当一个行被insert delete update的时候,直接找到对应的node,本地执行。这种方式适合于co-located join和等值查询
co-located join: 文件中相关的数据行在一个节点上,这样join的时候数据就不用在节点之间移动了,提高效率;
CREATE TABLE github_events
(
event_id bigint,
event_type text,
event_public boolean,
repo_id bigint,
payload jsonb,
repo jsonb,
actor jsonb,
org jsonb,
created_at timestamp
);
SELECT master_create_distributed_table('github_events', 'repo_id', 'hash');
- range Distribution
range 意思是所有的shard在distribution key上没有重合的range。默认的并不强制每个shard上没有重叠。 (append主要强调的是append-only),range分布的时候如果没有顺序需要排个序。
/opt/citusdb/4.0/bin/psql -h localhost -d postgres
CREATE TABLE github_events
(
event_id bigint,
event_type text,
event_public boolean,
repo_id bigint,
payload jsonb,
repo jsonb,
actor jsonb,
org jsonb,
created_at timestamp
)
-- DISTRIBUTE BY RANGE (repo_id);
SELECT master_create_distributed_table('github_events', 'repo_id', 'range');
查询执行
用户的查询请求,被master node分割成很多的查询片段,被发给每个shard,在每个shard上可以独立执行。这允许CitusDB来将每个查询分布到集群的各个节点上执行,用尽每一个参与节点以及参与节点的每个cpu。将查询请求发给每个节点后,Master负责监视节点的执行以及合并他们的结果,然后返回给用户;
为了保证所有的查询分布的行为是可扩展的,Master节点同时也应用了一些优化的手段来最小化节点之间的传输数据。
CitusDB的SQL查询计划分为两个阶段。 第一个阶段是将SQL转换成可交换的(commutative)、可组合的(associative)的形式。这样查询就可以下推到worker node来并发执行 第二个阶段就是在workernode上的PostgreSQL,来执行接收到的查询请求。
Aggregate Functions
如果是Distribution Column,那么就可以下推到每个节点执行。如果不是,那么需要重新划分底层数据。
针对这一问题,CitusDB提供了基于HyperLoglog算法,来计算非分布式列的近似值
Joins
对于大表和小表的Join执行策略是不一样的。一般来说,事实表是大表,维表是小表。
- Broadcast Join
大表和小表的Join,将小表复制发送到大表shard存在的node上,然后本地执行
- Colocated Join
两个大表Join ,满足条件 **Distributed Column上的Join,并且表是Hash Distributed **。 这样Master可以知道哪些shard和哪些shard是匹配的。排除掉不可能结果的shard之间的join。
- Repartition join
不满足上述条件的大表Join。增加一个repartition的shuffle过程。
citus的shard迁移方案
citus的社区版不支持Rebalance,也不支持move_shard;只有一个copyshard的方法;我们如果有moveshard的方案,就可以自己控制Rebalance了;这里自己探索了一个简单的方式,move shard;
\! pg_dump -s -t github_events_102072 > /tmp/github_events_102072.sql
\i /tmp/github_events_102072.sql
# 在元数据表上,插入一条新的记录,并标记这个shard为inactive,以及shard的新groupid
insert into pg_dist_placement(shardid , shardstate , shardlength , groupid) values (102088,3,0,1);
begin;
# lock old shard
lock shard_old_23425
# copy 这个shard
SELECT master_copy_shard_placement(102073, '10.9.144.141', 5433, '10.9.144.141', 5432);
# 标记老shard为inactive
update pg_dist_placement set shardstate = 3 where shardid = 102073 and groupid =3;
commit;
如果真正实现move,需要考虑锁的问题,其实citus的企业版已经实现了move的方法,但是社区版没有这个功能;
/*
* master_move_shard_placement moves given shard (and its co-located shards) from one
* node to the other node.
*/
Datum
master_move_shard_placement(PG_FUNCTION_ARGS)
{
ereport(ERROR, (errcode(ERRCODE_FEATURE_NOT_SUPPORTED),
errmsg("master_move_shard_placement() is only supported on "
"Citus Enterprise")));
}
经测试:
在两个node上,按照上述方法,创建同一个shard后,新的数据会双写;那么有如下可能的迁移方案
可能的方案:
需要将$4\times 64 $个shard;扩容到$8\times 32$组中;即,将一个node,拆成两个node;以其中一组为例;
按照上述方法,创建新shard的shema,此时新shard都是inactive的
\! pg_dump -s -t github_events_102072 > /tmp/github_events_102072.sql \i /tmp/github_events_102072.sql # 在元数据表上,插入一条新的记录,并标记这个shard为inactive,以及shard的新groupid insert into pg_dist_placement(shardid , shardstate , shardlength , groupid) values (102088,3,0,1);copy it;此时迁移的shard在集群中,有两份双写的数据;
SELECT master_copy_shard_placement(102073, '10.9.144.141', 5433, '10.9.144.141', 5432);将老node上的已经迁移的shard,标记为inactive;经测试,标记为inactive后,老shard片不再写入
update pg_dist_placement set shardstate = 3 where shardid = 102073 and groupid =3;
图1 老数据不再更新

方案中的问题
如果相应shard片正在写入,copy shard的过程中是否有数据不一致?
测试
postgres=# select get_shard_id_for_distribution_column('github_events',28229924);
get_shard_id_for_distribution_column
--------------------------------------
102085
(1 row)
postgres=# select * from pg_dist_placement where shardid = 102085;
placementid | shardid | shardstate | shardlength | groupid
-------------+---------+------------+-------------+---------
78 | 102085 | 1 | 0 | 3
(1 row)
测试方案,将102085分片从 groupid=3 迁移到 groupid=1;迁移过程中,在copy阶段采用事务的方式,执行插入,观察是否成功,以及此时的锁
发现insert等待,;
当copy事务回滚后,insert执行成功,但是,只有groupid=3的成功了,1并没有成功;但确实复制过去了,如图
postgres=# select * from pg_dist_placement where shardid = 102085;
placementid | shardid | shardstate | shardlength | groupid
-------------+---------+------------+-------------+---------
78 | 102085 | 1 | 0 | 3
101 | 102085 | 3 | 0 | 1
(2 rows)

insert 0 2 是因为我测试数据是插入两条,一个属于这个shard,一个不属于;
结论
在copy的过程中会对shard加锁(可读不可写);
附录
当copy成功后,两个shard都是可用的,shardstate=1;
COMMIT
postgres=# select * from pg_dist_placement where shardid = 102085;
placementid | shardid | shardstate | shardlength | groupid
-------------+---------+------------+-------------+---------
78 | 102085 | 1 | 0 | 3
101 | 102085 | 1 | 0 | 1
(2 rows)
master_copy_shard_placementIf a shard placement fails to be updated during a modification command or a DDL operation, then it gets marked as inactive. The master_copy_shard_placement function can then be called to repair an inactive shard placement using data from a healthy placement.
我们现在各个分片没有逻辑冗余片,而是采用pg自身的流复制冗余;关于这个copy函数本身的作用是,当有逻辑冗余片损坏是,repair用的;这里迁移的方法就是,手动做一个inactive的坏冗余片,利用这个
master_copy_shard_placement函数,将数据迁移过来,让后把老的inactive即可;

因此,迁移过程不必一次完成,可以慢慢的一个个观察着迁移;
回滚方案
由于可以灰度的迁移,如果出现问题可以及时回滚;针对某个shard的回滚方案如下:
# 其实就是讲新shard片inactive,将老shard片active;可能会有少量数据丢失,可以后期补回来
update pg_dist_placement set shardstate = 3 where shardid = thisshardid and groupid =newshardgroup;
update pg_dist_placement set shardstate = 1 where shardid = thisshardid and groupid =oldshardgroup;