IO Stack
进程通过文件抽象与底层设备的读写,每个进程的描述信息中有所有打开的文件,维护在一个数组中;该数据组的下标就是通常我们用到的fd,0、1、2分别对应stdin、stdout、stderr(可能不同的fd指向同一个file,这就是重定向)。
当进程读写文件时,由上到下分别经过VFS->FS->BlockLayer->driver,最后到达盘中,如下图:
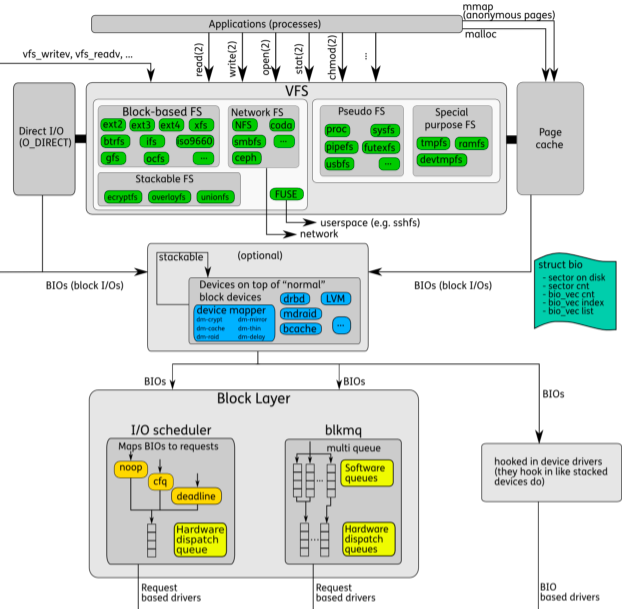
本文希望能用最少的语言将IO栈进行归纳,使得自己对整个读写流程涉及的模块有感性的认识。
VFS
首先是VFS,VFS提供了一套标准的文件接口,使得不同的文件系统之间能够统一的交互;VFS定义了文件系统需要提供的接口与对象,当Process访问一个文件时,通过定义的Objects,进行操作,这些对象可以看做是各个抽象层次的元信息(控制信息),有以下几类:
- SuperBlock:filesystem control block(FileSystem MetaData);
- inode:file control block(File MetaData),Linux中文件数据与信息分开存放,inode中有文件操作所需的所有信息,不包括filename信息。
- File :当Process访问文件时,Kernel创建File对象,保存访问时需要信息,其中持有一个dentry的指针。文件类型有:regular file、directory file、symbolic link、(Device file)、(pipe)。
- dentry:该结构没有对应的磁盘结构,是Kernel在内存中创建的并缓存在dcache中,代表路径的一部分,能够加速路径查找速度,和directory file 不是一个东西;dentry将filepath与inode相关联,创建hard link就是创建一个指向同一个inode的一个dentry。当Process访问一个文件时,如果dcache(LRU)中可以找到相应的dentry,那么将极大提高效率,否则Kernel将filepath相关的所有目录的dentry都创建出来,比如/tmp/test创建三个dentry,并将其Cache起来,如果dentry不在需要会回收到slab中。
- Memory region:mmap方式访问文件时,需要维护的内存区域信息。
总结来说VFS提供了一个标准接口,具体的FS实现各种操作对象的操作方法;每个FS有一个superblock,inode是与物理文件唯一相关的对象,多个dentry可以对应一个inode,而file是进程视角的文件,其中通过持有一个dentry指针映射到集体文件。
Caches
Disk Cache vs Swap
Disk caches enhance system performance at the expense of free RAM, while swapping extends the amount of addressable memory at the expense of access speed. Thus, disk caches are “good” and desirable, while swapping should be regarded as some sort of last resort to be used whenever the amount of free RAM becomes too scarce.
- Disk-based filesystems do not directly use the page cache for writing to a regular file. This is a heritage from older versions of Linux, in which the only disk cache was the buffer cache. However, network-based filesystems always use the page cache for writing to a regular file.
- The approach used in Linux 2.2, bypassing the page cache, leads to a synchronization problem. When writing takes place, the valid data is in the buffer cache but not in the page cache; 因此,disk based fs的write call,通过调用update_vm_cache来确保page_cache最新。
- Dentry cache:FilePathName -> inode
- Page Cache(PC):系统内所有页对象的缓存,不仅仅是面向文件;Page的来源用address_space表示,address_space可以关联inode,也可以关联其他内存映射,比如swapper;Page大小与物理disk block无关。
- Buffer Cache(2.6以后就没了,作为PageCache的一部分):之前同一份数据可能存在page cache和buffer cache中,需要两者的同步;
- Page的驱逐通过LRU/2进行管理,即维护在active_list、unactive_list中;通过flusher进程进行刷盘,每个设备一个flusher,理论上可以并发,但是需要考虑全局IO总线带宽的影响。
- 查询Cache是基于RadixTree而不是HashTree,前者占用内存更少,不需要全局锁。
再后来,BufferCache就消失了, 只剩了Page Cache。
FS(EXT4)
具体的文件系统通过挂载(mount)到某个路径上(dentry),值得注意的是同一个文件系统可以挂载不同的路径上,但是全局只有一个superblock;因此两个路径上的数据是相通的。
TODO
Block layer
![[Block layer diagram]](/image/linux-io/neil-blocklayer.png)
Block Layer在LinuxIO栈中处于承上启下的位置,是IO上传下达的疏导模块,其实可以分为两层:bio layer和Request layer。
Bio Layer
文件的读写syscall的create/open/link理论上只需要与vfs交互,定位到具体的磁盘与fs;read/write会真正的操作数据,就穿透到bio layer;bio之上是具体fs中的map layer(维护logical blocks到 physical blocks的映射)。
每个上层的r/w block操作,在bio layer封装成 bio结构;多个bio结构组成一个request,准备下发到device driver;具体的下发到device的逻辑定义在block layer的io scheduler中;
下发的时候如果Request queue没有位置可能会等待queue中的空间,而不是等待bio完成;这和REQ_NOWAIT是否设置相关。
另外,bio layer自身可以调整想device发request的rate,这种机制称为plugging(plug指的是plug queue when queue is empty);意思是在取queue lock,提交到queue之前,可以先合并多个小request,再提交到queue,这减少了整体的锁内时间,从而最大限度提高吞吐(见patch,2.6.39)。
Request Layer
有时候bio就直接可以将bio请求发送给device了,如图的md、dm等情况;而由于磁盘的寻道时间不可忽略,如果IO的大致有序的能大大提高全局吞吐,因此大部分情况可能还需要将Request进行Reorder,并且会将相邻的IO进行Merge,有效的利用IOPS,这就是Request layer的工作,具体的如何调度由不同的调度器实现,主要有四种:
- Elevator:最小化寻道时间,但是会存在某个IO长时间等待;
- Deadline:兼顾寻道时间的同时,增加额外的读写队列,确保额外的队列的头部即将过期时能够及时提交执行;
- Complete Fair Queue:按照进程分成不同的队列,使用时间片的方式来确保公平调度;主要用在桌面系统中, 确保各个应用的公平;
- Noop:当寻道时间可以忽略不计时,比如SSD,只做Merge不做排序,按FIFO的提交IO。
从文首的图的左下角可以看出,不管IO Scheduler基于何种策略下发Request,DispatchQueue只有一个;调度准备好后,通知driver可以将其下发了,driver通过回调通知上次某个Request完成了。
在当前的SSD中,有多个channel,硬件并发写多个channel;并且硬件可也根据自身的情况进行调度,这样其实kernel层的调度的意义就不大了,这促使Request layer变成multi-queue的架构。并且在多核架构的现在,核数越来越多,lock的开销变得比较重要;将single queue变成multi queue,做到per numa node或者per cpu core都可以提高整体的扩展性;并且底层的SSD也支持了parallel submit,这就更合理了;就算没有parallel submit,能够将请求merge成一个larger batch,也是有收获的。
在cfq scheduler中也提到了multi-queue,这里的multi-queue是面向process(或者priority level),解决的是process的公平性;这里的MultiQueue面向的时候device,包含两组队列:
- software staging queue:这是和CPU相关的,一般是per cpu或者per numa node;当block io被unplugged后,将其提交到这个队列中,这个队列也有自己的scheduler,比如:bfq/kyber/mq-deadline。
- hardware staging queue:这就是基于底层硬件的特性来分配了,可能是一个,也可能是多个;请求到了这个队列,就按序提交给driver了。
在5.0的Kernel中,已经是multi-queue-only了,将single-queue删除了。
Device (SSD)
SSD从大到小有如下层级划分:
层级之间的具体数量关注数量级即可,具体数值与厂商相关。
- DRAM chips
- logical address translation table
- NAND chips:用户拆开可见的黑色芯片盒子。
- die(chip):一个chips大概有8个die;芯片场造出的芯片,稠密度体现chip中,即die中。
- plane(strip):一个die大概2个plane;下层的block按照Raid0或者Raid1类似的方式组织的logical storage unit,有自己的寄存器和cache。
- block:一个plane大概有1000+个block;擦除的单位,也是gc的单位。
- page:一个block大概有100+个page;一般是4k,但是可能比4k大(与cell类型相关)。
- memory cell:TLC QLC。。
SSD主控通过memory channel链接到chips上,我们通常说的channel指的是连接到NAND chips的channel,这使得SSD有Parallel的能力。

不像传统磁盘,SSD主控会在内部做一些维护工作,比如GC。
TODO
APIS(TODO)
在Linux中,一切皆文件。数据都是通过fd标识进行交互;默认情况下,fd读取时如果没有数据,那么需要等待有数据了,此时当前进程状态变为sleep,那么称这个fd为blocking file descripter。这对于需要高吞吐的的应用是不适用的;为解决这个问题,我们可以将该fd变为非阻塞的:
/* set O_NONBLOCK on fd */
int flags = fcntl(fd, F_GETFL, 0);
fcntl(fd, F_SETFL, flags | O_NONBLOCK);
这时对于这个fd,读取立即返回(如果没有读取到数据,则返回一个错误信息),这就是non-blocking file descripter;进程不会sleep,但是我们需要不断检查是否准备好。
在实际情况中,通常我们需要管理多个fd(比如C/S架构中,server与client就有多个socket fd)。如果fd是blocking,那么需要多个线程(进程太重,在这里不太适用)分别管理每个blocking fd,这就是阻塞性同步IO,存在线程间信息同步的代价。
而将各个fd设置为non-blocking的,那么可以通过一个线程对各个non-blocking fd进行轮询,这就是非阻塞同步IO,但是这样浪费了CPU资源。
这时通常可结合IO multiplexing接口——select/poll/epoll,来对多个fd进行管理,当然这些fd中可以有阻塞,也可以有非阻塞的,只是实际应用中更多结合non-blocking fd使用。
epoll与select/poll的区别:
后者是各维护一个列表,采用轮询的方式进行事件触发管理,对系统内任何类型操作符都有效。
epoll是通过中断信号触发的方式管理,但是epoll只对流设备有效。
struct epoll_event { __uint32_t events; /* Epoll events */ epoll_data_t data; /* User data variable */ }; #include <sys/epoll.h> int epoll_create(int size); int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
epoll对文件描述符的操作有两种模式:LT(level trigger)和ET(edge trigger)。LT模式是默认模式,LT模式与ET模式的区别如下: LT模式:当epoll_wait检测到描述符事件发生并将此事件通知应用程序,应用程序可以不立即处理该事件。下次调用epoll_wait时,会再次响应应用程序并通知此事件。 ET模式:当epoll_wait检测到描述符事件发生并将此事件通知应用程序,应用程序必须立即处理该事件。如果不处理,下次调用epoll_wait时,不会再次响应应用程序并通知此事件。 ET模式在很大程度上减少了epoll事件被重复触发的次数,因此效率要比LT模式高。epoll工作在ET模式的时候,必须使用非阻塞套接口,以避免由于一个文件句柄的阻塞读/阻塞写操作把处理多个文件描述符的任务饿死。
注意通过多路复用的方式进行IO同样是同步IO,因为epoll只是监听了数据是否准备好,具体的处理程序还是需要将数据从系统空间拷贝到用户空间,这里需要同步等待。而异步IO是进程告知操作系统我需要哪些数据,操作系统在将数据直接拷贝到用户空间后才通知用户,这是根本区别。
有些操作系统并没有真正在内核层面支持异步IO,只是对该逻辑在系统库中进行了封装;在Linux中内核层面支持了,见下节。
Linux在2.6版的内核中支持了AIO特性,启用AIO特性需要以下前提:
在裸块设备上的读写(raw (and O_DIRECT on blockdev))。
或者,要求ext2, ext3, jfs, xfs文件系统的文件以O_DIRECT的方式打开。
在使用AIO进行读写时,需要按照如下框架进行调用:
io_setup初始化一个io_context_t。创建若干个IO请求(iocb)并设置好该请求相关的内容。
struct iocb { void *data; short aio_lio_opcode; int aio_fildes; union { struct { void *buf; unsigned long nbytes; long long offset; } c; } u; };io_submit:将创建好的IO请求提交到相应的io_context_t中;相应请求就被内核转发到driver中进行处理。io_getevents:调用该函数,获取发起的IO请求的结果。根据性能的需要,可调整传入的参数。重复以上操作可以进行文件的异步读写,最后通过
io_cancel,io_destory退出或销毁。
注意,在glibc中没有对上述系统调用进行封装,而是在libaio中进行了封装,如果使用了libaio中的函数,在编译的时候需要加上-laio;比如可通过libaio中的函数io_set_eventfd将iocb与eventfd绑定,这样可通过epoll进行触发调用io_getevents,而不是主动调用io_getevents确认结果。
在libaio中,在系统调用的基础上封装了多个函数如下,有兴趣可以了解一下。
static inline void io_prep_pread(struct iocb *iocb, int fd, void *buf, size_t count, long long offset) static inline void io_prep_pwrite(struct iocb *iocb, int fd, void *buf, size_t count, long long offset) static inline void io_prep_preadv(struct iocb *iocb, int fd, const struct iovec *iov, int iovcnt, long long offset) static inline void io_prep_pwritev(struct iocb *iocb, int fd, const struct iovec *iov, int iovcnt, long long offset) static inline void io_prep_poll(struct iocb *iocb, int fd, int events) static inline void io_prep_fsync(struct iocb *iocb, int fd) static inline void io_prep_fdsync(struct iocb *iocb, int fd) static inline int io_poll(io_context_t ctx, struct iocb *iocb, io_callback_t cb, int fd, int events) static inline int io_fsync(io_context_t ctx, struct iocb *iocb, io_callback_t cb, int fd) static inline int io_fdsync(io_context_t ctx, struct iocb *iocb, io_callback_t cb, int fd) static inline void io_set_eventfd(struct iocb *iocb, int eventfd);
io_uring
TODO
小结
在日常工作中,涉及的IO一般就包括两种:磁盘的读写、网络的读写。对于磁盘文件的读写通常,目前想到的有以下几个方案:
- 通过专门的IO工作线程池来做这个工作,可以调用glibc POSIX AIO接口,其就是对这个逻辑的封装。
- 通过
posix_fadvise对一段磁盘文件进行预热。 - 使用mmap将磁盘文件映射进内存
- 使用Linux AIO,文件需要以
O_DIRECT的方式打开。
这些方法都不是完美的,即使是Linux AIO,如果使用不恰当,也会阻塞在io_submit中。那么具体使用什么方案,可以具体情况进行分析。而对于网络IO通常是epoll监听非阻塞socket fd,转给线程池进行处理的方式。
参考