这个标题起的有点大,其实就是作为一个C++11的小白,希望能够对Modern C++ (本文就是C++11)标准提供的Concurrency工具,增强一下理解。想要了解Modern C++的Concurrency,笔者觉得要从三方面去了解:执行对象、同步原语和内存模型;那么,本文就从背景原理入手,来一一了解他们。
Executor Object
首先就是执行对象,对于操作系统来说并发程序的执行对象都是其调度的task,但是在用户来看有进程,有线程,这里只讨论线程,通常可认为线程就是基于pthread库来进行调用,没找到特别值得说的。主要有一点,当线程资源有限的时候,如果某些线程处于blocking状态,比如正在等待IO,那么其实资源是有浪费的;
针对此种场景,有人提出了协程,协程相比于线程的好处在于可以主动让出CPU(yield),这样在同一个线程中,可以有多条执行任务互相协作完成整体工作;不过在标准中,那得C++ 20才有,当前只能用各种第三方库,比如Fiber,Fiber的调度方式是主动的,并且是用户态进行context switch,更加轻量级(需要更少的CPU指令);fiber的调度通过fiber_manager管理,当fiber执行yield或者suspend等让出控制权的操作时,manager就会调度下一个fiber执行。
注意,Boost:Fiber需要C++11的支持;
在Modern C++中,线程就是对pthread进行了封装,使其更加C++ style,而不是C style;不过少了一些接口,有时候还需要直接调用pthread的函数。
Synchronization primitives
其次,Concurrency必然要解决data race的问题,最简单直观的来说就是加锁;而锁的实现需要系统提供同步原语,按照底层实现机制大致分为两类:基于syscall封装的锁和基于hardware提供的原子操作封装的锁;
现在的CPU架构中,都有原子操作,一般锁可基于原子操作实现;而早期计算机,比如PostgreSQL的早期自旋锁实现是基于sem_trywait()的,后面当底层硬件架构支持原子操作后,才有了第二个版本(src/include/storage/s_lock.h);PostgreSQL 在9.6版本中,将 bufferpool 中的 spinlock 替换为 atomic operations,其将 refcount 设计成一个原子变量,借助底层的 add_fetch 原子指令进行操作,这样能够减少锁的额外代价;同样地,在 InnoDB 5.7的 os0sync 中同样封装了原子操作,在8.0中,则直接使用了 C++11 的原子类型。
pause (rep nop)指令
实现基于原子操作的自旋锁时,除了原子操作之外,有时还有一个pause指令。其就是告诉CPU当前指令位于spin lock中,CPU避免进行cache缓存、指令重排与预测,这样CPU的效率会高一些。在spin lock场景中,等锁的core不断执行load,执行了几次都失败后,系统按照常理推测出后续应该都失败,就按照失败的逻辑排列了load指令;但是可能刚排列好,另一个core就解锁了,即,执行了store命令;那么spink lock 对应的load流水线,就得重排;为了避免这个代价,intel的cpu引入了pause指令,这样load先不着急预测排列。
而基于原子操作实现的自旋锁,其本身的需要一直占用CPU,在低冲突的场景中,cpu-user的代价比较高,并不适用;而基于syscall的锁,如果频繁切换上下文的开销,其cpu-sys代价就高,因此有时大家会采取两种技术结合的方案(参见RocksDB的WriteThread);而这只是减少的切换上下文的次数,并没有真正减少切换上下文的时间,因此,在2003年,IBM的工程师缓解这一问题,向kernel中引入了新的syscal——futex:
#include <linux/futex.h>
#include <sys/time.h>
int futex(int *uaddr, int futex_op, int val,
const struct timespec *timeout, /* or: uint32_t val2 */
int *uaddr2, int val3);
futex是Fast Userspace muTEX的简称,主要用于共享内存场景下的减小多线程程序中锁同步时system call的代价。多线程模型下,天然就是共享的,对于多进程模型,可以应用在mmap(2) 或 shmat(2)创建的共享内存上。futex_op参数定义了多种不同的操作,比如FUTEX_WAIT和FUTEX_WAKE,一个是等待uaddr处的数据等于val,一个是唤醒等待的线程(进程)。
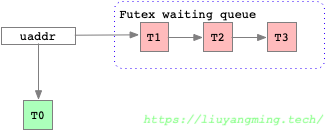
其由内核帮用户态线程维护了一个锁队列,如上图,线程通过FUTEX_WAIT通知内核将自己挂起并排队,然后由另外一个进程通过FUTEX_WAKE释放该锁,并唤醒队列中的线程(唤醒时,可通过参数指定唤醒数量)。在实际代码中,比如glibc中的pthread_mutex_t(glibc/sysdeps/nptl/lowlevellock.h),其结合futex 和 atomic operation来实现锁;当锁上没有持有者,可以直接基于atomic取锁;当有已有持有者,才使用futex进行排队。
Modern C++
和thread类似,C++ 11封装了pthread中的锁模型,使其更加的C++ style;另外还提出了atomic类型,只要可以trival copyable的类型都可以atomic;通过atomic类型,编译器确保该变量可以原子的访问;但是取决于CPU的alignment、padding等因素,可能不是lock_free的,编译器底层依然还是基于锁实现的,这个可通过**atomic

值得注意的是,原子操作会对齐cacheline;比如std::atomic
特别值得关注的一个原子操作是
compare_and_swap,因为这是实现lock-free structure的基本操作。cas是read modify write,先load 后 store,在std中提供了weak和strong两种操作类型,weak主要的语义就是有可能发生spurious failure,这是因为后续的store相比load,其需要互斥写对应内存地址,互斥写可能存在等待。如果程序中可以容忍这种行为,那么可获得一点优化;因此可将weak理解成store阶段有个time_lock,超时就返回了,而strong则一直等待直到成功(不过这取决于硬件实现相关,X86的weak行为也是strong)。
只是将pthread进行封装,编程模型上还是1980年代的模型,更加modern 的语言中已经提供了更加上层的线程间同步的抽象,比如golang的channel,在Modern C++中,也做了相应的改变,就是promise & future;promise 和 future可看做是一个单向传输的管子,promise是入口,future是出口。这个管子可以带进thread的function中,function执行完成后,将相应结果放到管子里即可;需要读取该信息的thread持有future即可,通过future.get获取执行结果。当然这些过程除了显式的开启thread执行外,还可以通过packed_task和async的封装执行,这都是C++ 11的赋能!😄。
Memory Consistency Model
上面介绍的都是从CPU角度参与并发的对象,而并发的数据都在内存里;由于CPU乱序执行以及编译器的reorder优化,内存的访问会与我们程序预期的不一致,CPU和编译器会保证单线程背景下的正确性,而在并发场景下,这会出现问题。这时就需要考虑内存的顺序一致性的问题。
内存对于CPU来说,可认为是一个状态机,内存对于所有CPu core应始终保持顺序一致性(Sequential Consistency);在Sequential Consistency要求下,只要保证每个CPU看到的状态机变化的order是一致就行,不需要保证任一时刻所有CPU都是看到同一个数据快照。
常和Sequential Consistency相比的概念是Linearizability(线性一致性),Linearizability是从全局timestamp order上观察状态机的变化,要求在某个timestamp下,各个外部观察者看到的是一个一致的状态;
我们都知道CPU和内存之间还有一层cache系统,CPU以cacheline为粒度读取内存;不过cache对程序员应该透明的,不同cache之间的同步有专门的cache coherence协议(经典的就是MESI);我们讨论memory consistency model的时候暂时不需要考虑cache coherence的存在。
那么回到memory consistency model的主题上来,memory consistency目标是内存这个状态机对于所有的cpu core是保持Sequential Consistency;基于这样的假设,并发程序中另一个线程才能相信事件的发生顺序是可信的。最简单的就是完全不要乱序,那么性能肯定受影响,因此在不同架构下会在某些场景下放松尺度;通常我们也就只需要保证核心的一部分代码的顺序,则需要添加相应的memory barrier;
这里又能区分两个概念,memory order 和 memory barrier,可以认为memory barrier就是实现memory order的工具。
memory barrier有两个作用:防止指令乱序、确保数据可见;这里memory barrier可以是显式的fence指令,比如sfence、lfence以及mfence;也可以是隐式的操作,但是会带有memory barrier的作用,比如IO操作,exch、以及带有lock前缀的指令;这里以显式的fence指令来做说明。
比如,为了防止指令乱序,当插入sfence指令后,sfence之前的store指令都不会重排到sfence之后,并且如果,在执行sfence的时刻,store buffer中有store指令,那么会将store buffer挤干(drain)确保数据可见;为了保证数据的可见性,这里会和cache coherence协议发生联动;
其实也不需要对cache coherence有特别细节的了解;这里只需要知道,在cache coherence协议中,一个core对cacheline发生的写操作,那么会向其他core发送invalid Request;其他core收到invalid Request后,将cacheline标记为invalid后,会去内存读;这样保证了不同core不会读取到脏的内存数据。为了优化invalid这个操作,在x86 arch中,增加了Store buffer和Invalid queue的组件。此时,若当前CPU在自己的storebuffer中修改了某个cacheline,会向其他CPU发invalid Request;其他CPU收到invalid Request,先放到自己的invalid queue中,之后异步的将自己的cache line置invalid。当有这两个结构后,CPU读数据,会先读自己的store buffer,然后才是cacheline;其他CPU则不会得知此次修改,且由于cacheline的invalid是异步的,那么可能会极短的时间其他内会读到脏数据。

那么当有写barrier指令时,需先将StoreBuffer写到cache,确保barrier对应的指令执行时,其前面的store已经在cache内可见,这样就保证了内存在barrier处的状态始终只有我们要求的一种,即满足store指令不会乱序的哪一种;当有读barrier指令时,自身执行的时候,确保将invalidate queue的消息完成,那么也不会读取到脏数据。
不同硬件架构规定了不同的Memory Model;如果所有核上的指令几乎完全无序就是Weak Order;如果对于不同内存地址上的可以reorder,同一地址上保证顺序,这是relaxed order;如果同一个核上的对任何地址的Store都保序,这就是Total Store Order(TSO)。通常来说我们认为ARM就是完全的weaking order(几乎所有操作都可以reorder),X86、AMD相比Arm严格。
针对编译器的reorder,通过插入编译的barrier指令,或者一些关键字(volidate)可以防止其reorder;而在c++中volidate只用在编译器的reorder行为的约束。
Modern C++
为了使C++开发者编写并发代码时,能够保证乱序背景下的正确性,C++11将封装出memory order,其通过避免编译器对关键变量的优化以及插入必要的指令等手段,我们可确保了关键内存的读写顺序一致性。这样在并发环境中,才能确保行为符合预期。有以下六种:
memory_order_relaxed:不对执行顺序做任何保证;memory_order_acquire:后续的所有读操作需要在当前指令结束后执行;memory_order_release:之前的所有写操作都完成后,才能执行当前指令;memory_order_acq_rel:结合上两条;memory_order_consume:本线程中,后续与本原子变量相关的读写操作,必须在本指令完成后执行;memory_order_seq_cst:全部读写都按顺序执行,默认值,即保持Sequential Consistency;
一般通过多个原子操作上配置上不同的barrier,就得到了我们想要的多线程间的内存存取的语义,主要的有以下四种:
- release-acquire内存模型:
memory_order_acquire和memory_order_release经常结合使用,这种内存顺序不仅限于原子内存访问指令,包括普通内存访问指令;比较经典的一个例子就是解决cpp中Singleton的DoubleLockChecking的问题。 - release-consume内存模型:
memory_order_consume是memory_order_acquire的更加弱化版本,memory_order_release和memory_order_consume可以建立关于某原子变量的生产者-消费者顺序; - 松散内存模型:
memory_order_relaxed只保证原子变量访问的互斥即可。 - 顺序一致型内存模型,默认的完全保序模型。
举几个自己碰到的例子:
MySQL 8.0 中,对log模块的重构包括了无锁日志缓冲区,其中就通过
atomic_thread_fence进行内存顺序的保证,比如在log_buffer_close的时候,通过memory_order_release确保了在logbufferclose提交lsn时,lsn已经被正确的更新了。除了通过
atomic_thread_fence来指定之外,也可在原子变量的成员函数上附加barrier信息来达到barrier的效果,这种基于atomic_flag可用来构建上面某种内存模型,比如RocksDB的skiplist的SetNext构建了release-acquire内存模型;当插入一个新节点x的时候,由于有release-barrier,next_[n]更新的时候storebuffer会强制flush到cache中;此时cache的mesi协议会向其他cache发送invalid消息;invalid queue中的消息是异步apply的,不过当其他core的读操作遇到acquire-barrier时,会先把invalidqueue消费完再读cache;这样其他cache的内存状态也确保是准确的;在RocksDB中有时候只需采用relaxed,同样提供了Nobarrier_setNext保证互斥即可,根据不同场景取用。// Accessors/mutators for links. Wrapped in methods so we can // add the appropriate barriers as necessary. Node* Next(int n) { assert(n >= 0); // Use an 'acquire load' so that we observe a fully initialized // version of the returned Node. return (next_[n].load(std::memory_order_acquire)); } void SetNext(int n, Node* x) { assert(n >= 0); // Use a 'release store' so that anybody who reads through this // pointer observes a fully initialized version of the inserted node. next_[n].store(x, std::memory_order_release); }
因此C++ 11中,程序员只需要理解了上述memory order的定义,那么不需要深陷在架构具体细节,可以专注在自身的逻辑中。
大概就是这样,主要从是三个方面来了解了一下,C++ 11的Concurrency,可以看出C++ 虽然是个很老的语言,至今已经快30年的历史了,但是仍然在不断推陈出新,保持竞争力;但是很多教科书上甚至一直没有更新,如果想从事C++方向的开发,还是应该了解一下Modern 的世界。
